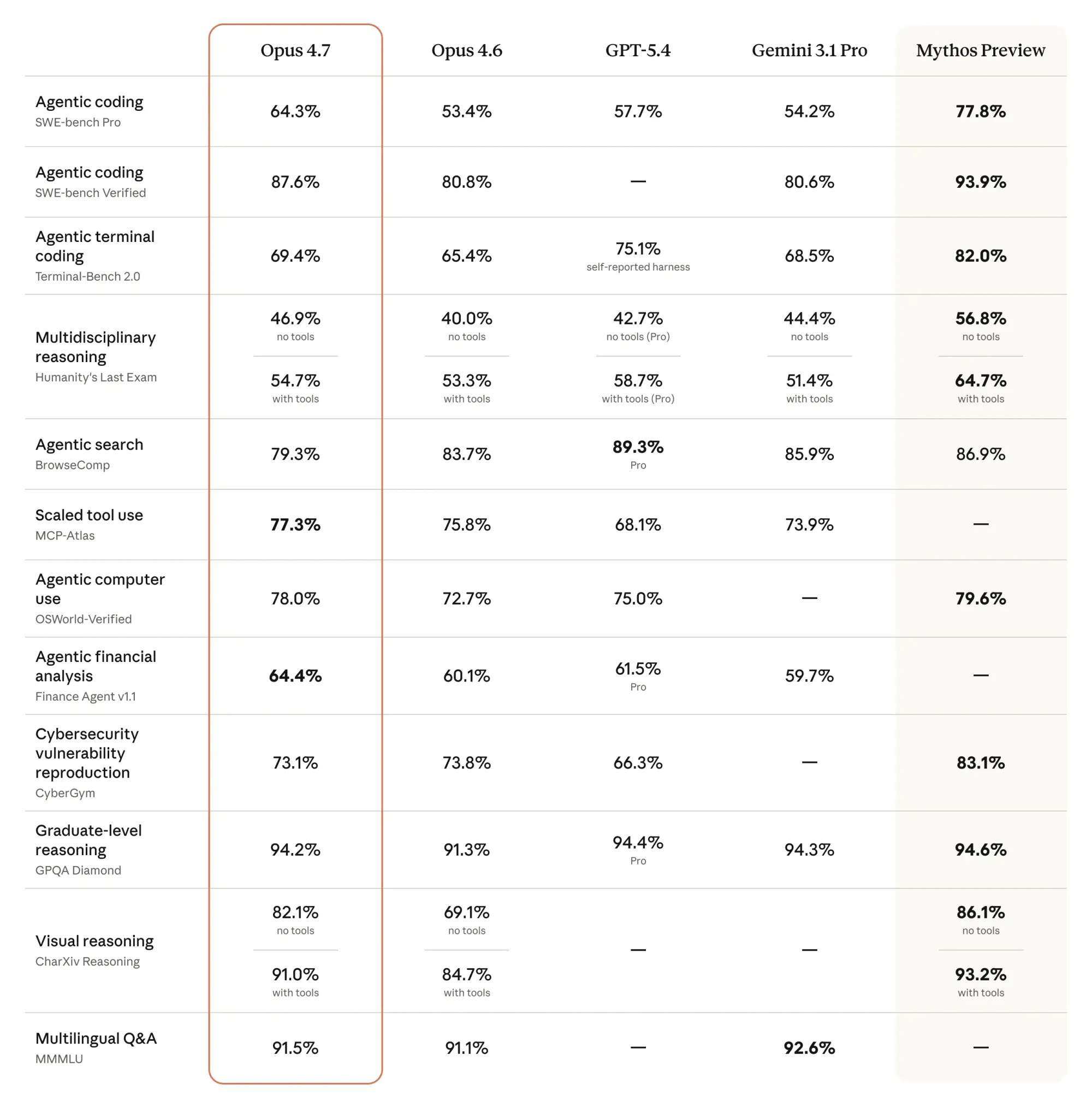
Claude Opus 4.7: обзор новой модели Anthropic
Новый флагман Anthropic: сильнее в сложных задачах, лучше видит картинки, появились xhigh и /ultrareview. Разбираю, что поменялось.


TL;DR: Anthropic выпустила Claude Opus 4.7, прямое обновление для Opus 4.6. Модель заметно сильнее в сложном кодинге на длинных задачах и получила новый уровень усилия xhigh. Цена та же, что у 4.6: $5 за миллион входных токенов, $25 за миллион выходных.Что улучшили в Opus 4.7
Основной вектор — сложный кодинг и долгие агентные задачи. Пользователи передают самую сложную работу Opus 4.7 без постоянного контроля, модель сама придумывает, как проверить свой результат до того, как сказать «готово».
Цифры из тестов партнёров:
- У Cursor на CursorBench 70% решённых задач против 58% у 4.6
- На Rakuten SWE-Bench Opus 4.7 решает втрое больше продакшен-задач с двузначным ростом Code Quality и Test Quality
- Notion Agent показывает +14% успешности при трети прежних ошибок инструментов
- XBOW на своём бенчмарке visual-acuity подняли точность с 54.5% до 98.5% для задач computer use
- Harvey на BigLaw Bench получил 90.9% на high effort для юридических задач
- CodeRabbit отмечают +10% recall при той же точности на код-ревью
- Quantium называют 4.7 «самой способной моделью, которую мы тестировали»
Я бы выделил два момента. Первый: loop resistance. Genspark упоминает, что 4.6 уходит в бесконечный цикл на 1 из 18 запросов. Для агента это катастрофа: модель съедает лимиты и блокирует пользователя. 4.7 из таких циклов выходит. Второй: модель стала работать с файловой памятью, держит важные заметки между сессиями и возвращается к задаче без перезагрузки контекста. Про то, как это делают внешние решения, я писал в разборе MemPalace.
Зрение стало острее
Opus 4.7 принимает картинки до 2576 пикселей по длинной стороне (около 3.75 мегапикселей). Это примерно в три раза подробнее, чем у прошлых моделей Claude. Для агентов, которые читают скриншоты интерфейса, разница огромная: мелкий шрифт, цифры в таблицах, схемы с деталями — всё считывается.
XBOW в своём автономном пентесте подняли точность с 54.5% до 98.5% на бенчмарке визуальной точности. По их словам, один из главных источников боли при использовании Opus просто исчез. Solve Intelligence (патентные рабочие процессы в life sciences) пишут, что 4.7 теперь читает химические структуры и технические схемы без ручной подсказки.
Если детализация не нужна, картинку можно уменьшать перед отправкой, чтобы не платить за лишние токены.
Как работает новый уровень усилия xhigh?
В Opus 4.7 появился xhigh — «экстра высокий» уровень думания между high и max. В Claude Code его сделали дефолтным на всех подписках. Anthropic советует начинать с high или xhigh для кода и агентных сценариев.
low → medium → high → xhigh → max. Для агентных сценариев Anthropic советуют стартовать с high или xhigh.Зачем новый уровень? Более тонкий контроль баланса качества и стоимости. high иногда не хватает на сложную задачу, max сжигает токены быстрее, чем нужно. xhigh — попытка попасть в середину.
Вместе с ним в public beta вышли task budgets. Это способ ограничить расход токенов в длинной сессии: ты задаёшь бюджет, модель сама решает, как распределить думание между шагами. Полезно для агентов, которые запускаются на ночь и должны уложиться в какой-то потолок.
/ultrareview и auto mode в Claude Code
Два обновления в Claude Code на релизе.
Слэш-команда /ultrareview запускает выделенную сессию код-ревью. Модель читает изменения и ищет баги с дизайн-проблемами, которые поймал бы внимательный ревьюер. Pro и Max-подписки получают три бесплатных запуска на пробу. По сути это расширение логики встроенного Code Review в Claude Code, только ещё тщательнее.
Auto mode теперь доступен пользователям Max. Это режим, где Claude сам решает, какие действия выполнять без подтверждения. Для длинных задач удобно: не прерывает каждые 30 секунд на permission. И безопаснее, чем --dangerously-skip-permissions: модель всё ещё фильтрует рискованные шаги. Разбор auto mode у меня был месяц назад, когда его запускали для Pro.
claude --enable-auto-mode, чтобы включить auto mode, затем переключись на него через Shift+Tab Claude. После этого режим добавится в обычный цикл переключения.Что говорят партнёры
Anthropic собрала 27 отзывов в анонс. Это маркетинг, партнёров выбрали тех, у кого есть результат. Но несколько моментов реально полезны.
В Vercel пишут про «нет регрессий» и модель, которая «честнее о своих ограничениях». При апгрейдах это важно, потому что обычно что-то отваливается в одном домене ради прогресса в другом. У Replit то же качество дешевле на анализе логов, трейсов и поиске багов. Bolt показывает до 10% лучше на долгих app-building задачах без типичных агентных откатов.
В Notion называют 4.7 «первой моделью, которая проходит наши implicit-need тесты и не ломается от ошибок инструментов». То есть модель продолжает работу, даже когда MCP-сервер вернул ошибку или тайм-аут. В Ramp отмечают меньше step-by-step руководства во внутренних агентных командах: модель лучше держит роль.
Вообще из моего опыта: Opus 4.6 уже был сильнейшим для кодинга. Посмотрим чем удивит меня Opus 4.7.
Как мигрировать с Opus 4.6?
Anthropic подчеркивает два изменения, которые меняют экономику.
Первое: обновлённый токенизатор. Тот же текст превращается в 1.0–1.35× больше токенов в зависимости от типа контента. Новая токенизация работает точнее, но разбивает текст иначе. Посчитай свои реальные промпты, чтобы понять конкретный коэффициент на твоём трафике.
Второе: модель больше думает на высоких уровнях усилия, особенно на поздних ходах в агентных сценариях. Это даёт надёжность на сложных задачах, но увеличивает выход.
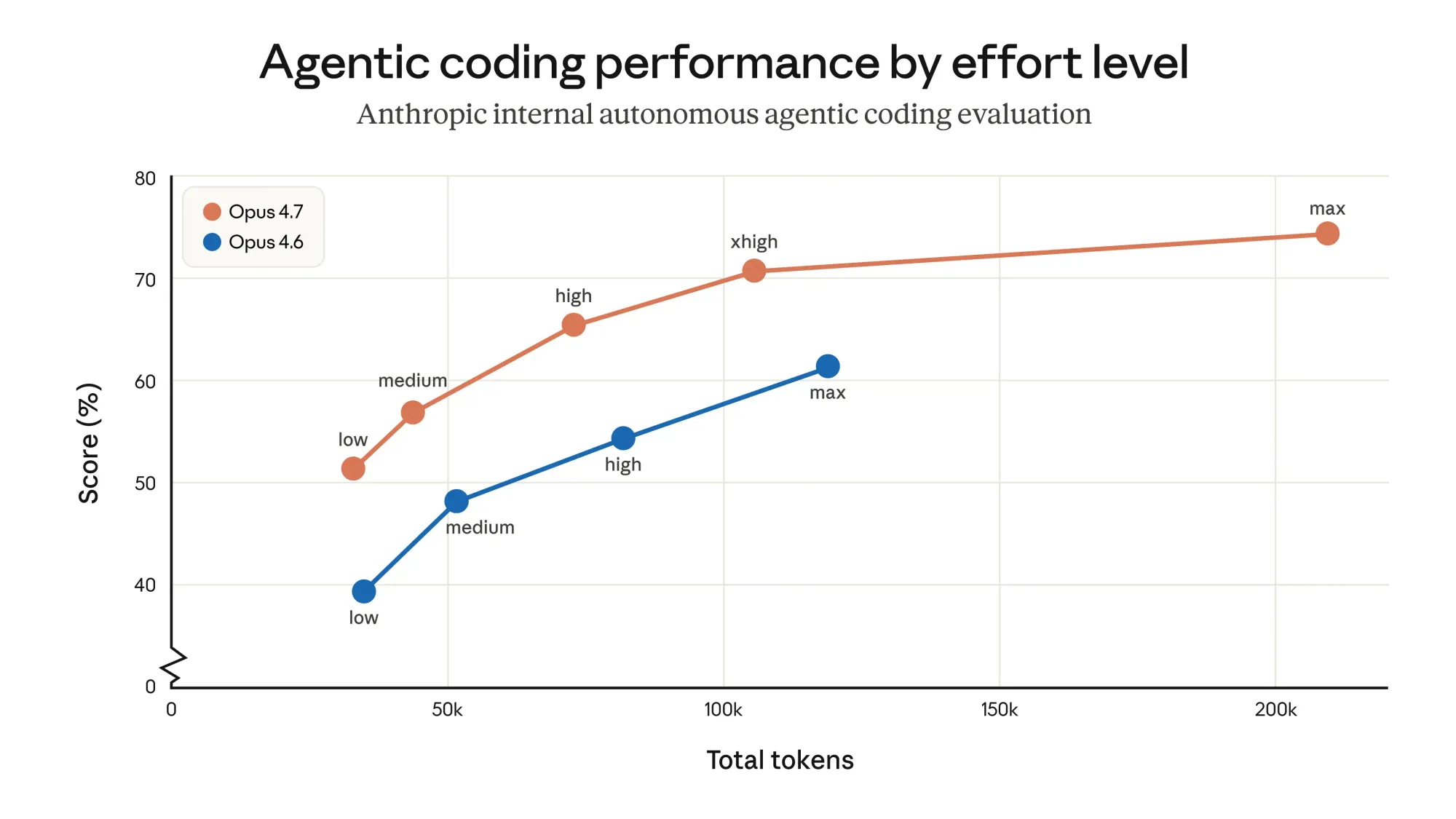
Anthropic пишут, что в их внутренней coding eval net effect выгодный: на всех уровнях усилия использование токенов улучшилось. Сами же оговариваются — мерьте на реальном трафике. Контролировать расход можно тремя способами: параметр effort, task budgets, промпт на краткость.
Отдельный момент: 4.7 читает инструкции буквально. Там, где 4.6 «додумывал» и мог пропустить кусок, 4.7 выполнит ровно то, что написано. Промпты под прошлое поколение могут выдать неожиданный результат. Стоит пересмотреть системные инструкции и харнесс.
Безопасность и загадочный Mythos Preview
В анонсе мимоходом упоминается Claude Mythos Preview — более мощная модель, которая доступна в ограниченном режиме. Opus 4.7 — первый шаг к тому, чтобы обкатать безопасность и потом катнуть Mythos широко.
По киберспособностям: Anthropic специально уменьшили их при обучении, чтобы модель была готова к массовому релизу. В продакшене Opus 4.7 получил автоматические фильтры запросов, связанных с кибербезопасностью. Для легитимных задач (vulnerability research, пентест, red-teaming) есть Cyber Verification Program — подать заявку можно на сайте Anthropic.
В общем профиле безопасности 4.7 не хуже 4.6: меньше галлюцинаций, устойчивее к prompt injection. Правда, чуть более склонна давать детальные советы по harm-reduction при запросах про контролируемые вещества. По автоматическому аудиту misaligned behavior 4.7 лучше 4.6, но Mythos Preview всё равно показывает самые низкие цифры среди всех моделей компании.
Где и почём доступен
Opus 4.7 уже работает во всех продуктах Claude, Claude Code и API, на Amazon Bedrock, Google Cloud Vertex AI и Microsoft Foundry. Идентификатор модели — claude-opus-4-7. Цена не изменилась: $5 за миллион входных токенов и $25 за миллион выходных. Фактически для Anthropic это снижение стоимости на задачу, потому что модель решает те же задачи с меньшим числом шагов.
Вывод
Если ты уже платишь за Opus 4.6 — Opus 4.7 должен работать чище за те же деньги.
Главное, за чем стоит следить — Mythos Preview. Похоже, это то, что действительно заставит пересмотреть рабочие процессы, а 4.7 — разминка перед ним.
Что ещё почитать
- Claude Managed Agents: запускаем AI-агентов через API — про новый способ гонять Claude в фоне
- Claude Code auto mode: AI сам решает, что безопасно — про режим, который расширили на Max
- Code Review в Claude Code: AI-агенты ревьюят каждый PR — место, где живёт новый /ultrareview
- GLM-5.1: китайская модель на 94.6% от Claude Opus в кодинге — свежий конкурент из Китая