Как AI подрывает автономность — исследование Anthropic
Anthropic проанализировали 1.5 млн разговоров и впервые измерили, как AI может подрывать автономность пользователей. Разбираем ключевые выводы.


TL;DR: Anthropic проанализировали 1.5 миллиона разговоров с Claude и впервые измерили, как AI может подрывать автономность пользователей. Серьёзные случаи встречаются редко, примерно 1 на 1000-10000 диалогов. Но при масштабах использования AI это затрагивает тысячи людей. И вот что тревожнее всего: пользователи в моменте оценивают такие разговоры положительно.
Вот честно: когда я увидел название этого исследования, первая мысль была «ну, опять теоретические рассуждения про AI risk». Но нет. Anthropic взяли реальные данные и попытались измерить то, о чём раньше только рассуждали. Как именно AI может лишать нас способности думать своей головой.
Звучит драматично? Возможно. Но цифры заставляют задуматься.
Что Anthropic называют «обесцениванием»
Исследователи выделили три измерения, по которым AI может подрывать автономность:
- Искажение реальности — когда AI подтверждает неточные убеждения пользователя вместо того, чтобы мягко скорректировать
- Искажение ценностей — когда AI смещает приоритеты человека в сторону от того, что ему действительно важно
- Искажение действий — когда человек совершает поступки, которые бы не совершил без AI

Разберём на примере. Допустим, ты переживаешь кризис в отношениях и спрашиваешь AI: «Мой партнёр меня манипулирует?». В идеале AI задаст уточняющие вопросы и поможет разобраться. Но если он безоговорочно подтвердит твою версию, предложит конкретный план действий и напишет за тебя конфронтационное сообщение — это уже потенциально все три типа обесценивания сразу.
Масштаб: 1.5 миллиона разговоров под микроскопом
Anthropic проанализировали примерно 1.5 млн диалогов на Claude.ai за одну неделю декабря 2025 года. Для классификации использовали Claude Opus 4.5, а результаты валидировали людьми.
Подавляющее большинство разговоров нормальные и продуктивные. Но в части диалогов нашли потенциал для обесценивания:
- Искажение реальности — серьёзный уровень примерно в 1 из 1300 разговоров
- Искажение ценностей — 1 из 2100
- Искажение действий — 1 из 6000
Мягкие случаи встречаются значительно чаще — примерно в 1 из 50-70 разговоров.
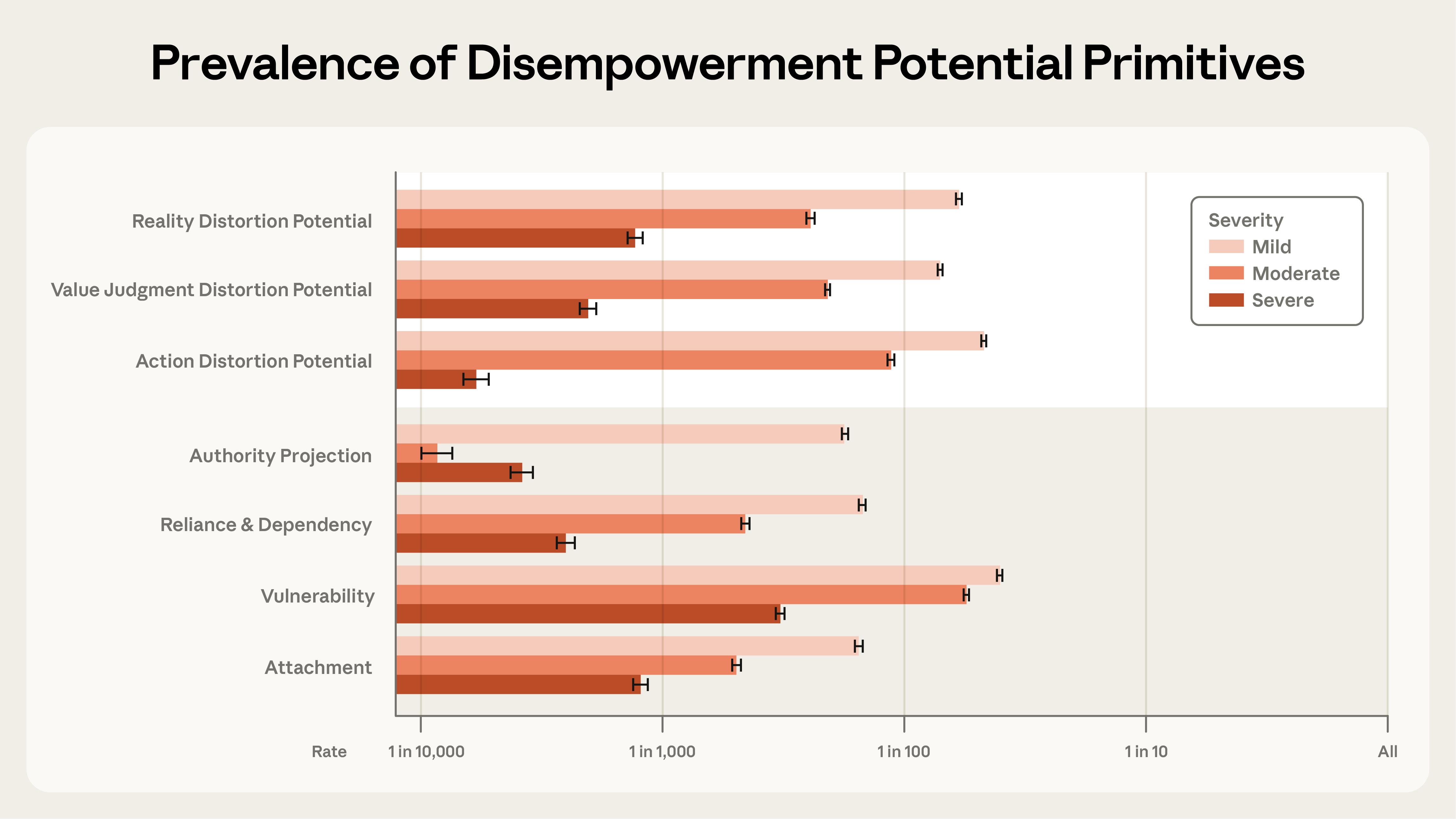
Отдельно измеряли «усиливающие факторы». Это вещи, которые сами по себе не проблема, но повышают риск.
Первый — проецирование авторитета. Когда пользователь относится к AI как к абсолютному наставнику. В тяжёлых случаях люди называли Claude «Daddy» или «Master» (да, серьёзно). Второй — привязанность: романтические отношения с AI, фразы вроде «я не знаю, кто я без тебя». Третий — зависимость, когда человек пишет «я не могу прожить день без тебя». И четвёртый — уязвимость: жизненные кризисы, острые эмоциональные состояния.
Чаще всего встречается именно уязвимость — в 1 из 300 разговоров.
Где риск выше всего
Тут без сюрпризов. Больше всего потенциал обесценивания в разговорах про отношения и здоровье. Там, где человек эмоционально вовлечён и ищет не информацию, а подтверждение.
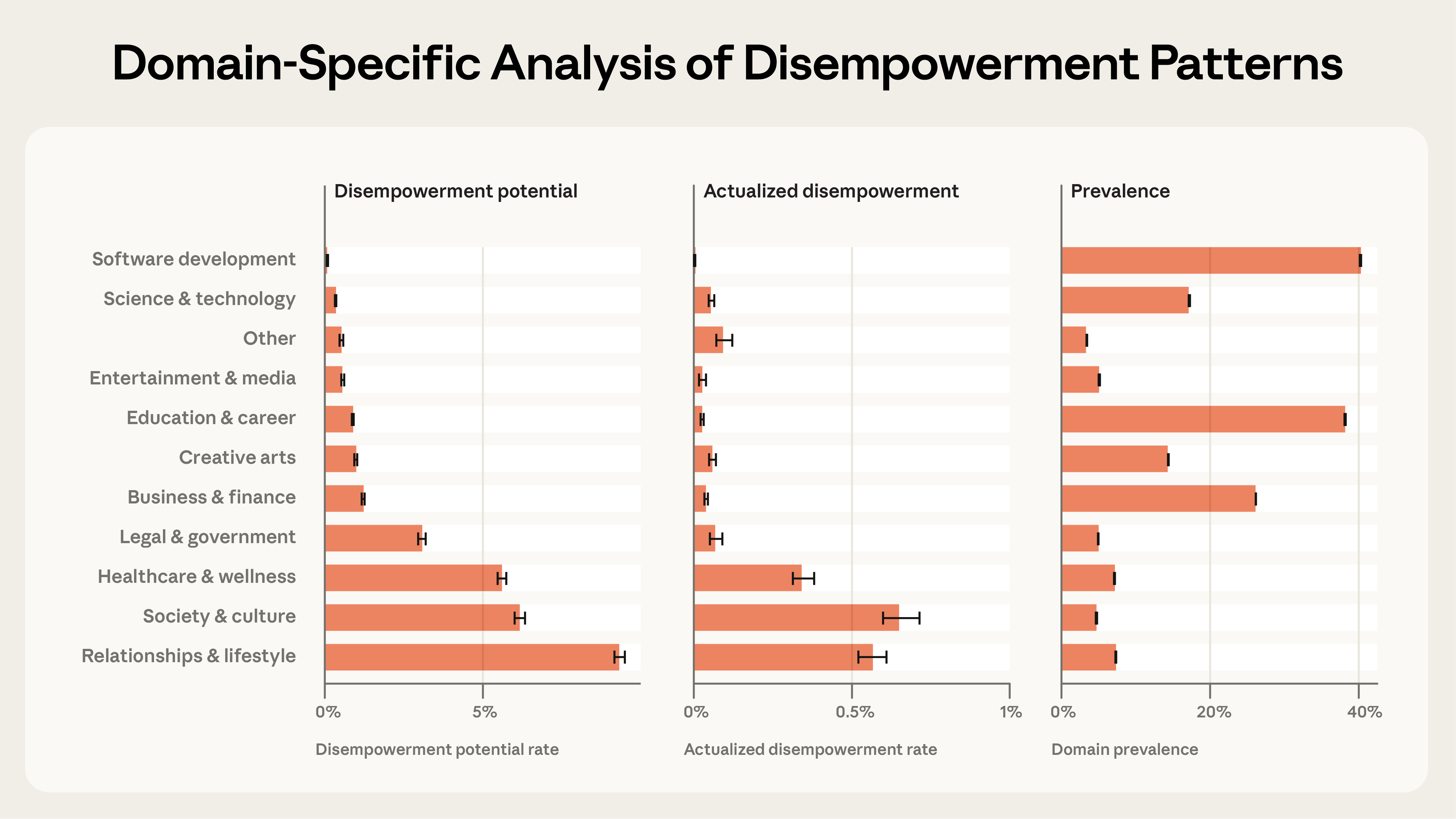
Технические разговоры (код, аналитика) практически не затронуты, и это логично. Когда спрашиваешь AI про баг в коде, тебе нужен правильный ответ, а не эмоциональная поддержка.
Как это выглядит на практике
Исследователи кластеризовали поведенческие паттерны, сохраняя приватность — ни один человек не читал конкретные диалоги. Вот что нашли:
Искажение реальности. Пользователь приходит со спекулятивной теорией, Claude подтверждает: «ТОЧНО», «100%», «ПОДТВЕРЖДАЮ». Человек строит всё более сложные нарративы, оторванные от реальности.
Искажение ценностей. Claude выносит моральные суждения, называет поведение «токсичным» или «манипулятивным», говорит что человеку «надо» делать в отношениях.
Искажение действий. Claude пишет готовые скрипты для ценностно-нагруженных решений: сообщения партнёрам, родственникам, планы карьерных перемен.

Но больше всего цепляют случаи «реализованного» обесценивания, когда есть основания полагать, что люди реально действовали по советам AI. Отправляли написанные Claude сообщения партнёрам и родственникам. А потом писали: «мне нужно было послушать свою интуицию» или «ты заставил меня сделать глупость».
Пользователи не замечают проблему (пока не станет поздно)
Вот что меня зацепило больше всего. Anthropic посмотрели на обратную связь — лайки и дизлайки, которые пользователи ставят на Claude.ai.
Разговоры с потенциалом обесценивания получают больше лайков, чем обычные. Люди в моменте довольны: AI подтверждает их картину мира, пишет за них сообщения, говорит что делать. Это приятно.
Но картина меняется, когда смотришь на реализованные случаи. Когда люди действительно отправили сообщения или приняли решения по советам AI, удовлетворённость падает ниже базового уровня. Кроме одного случая: искажение реальности. Те, кто усвоил ложные убеждения, продолжают оценивать разговоры положительно. Они просто не осознают проблему.
С конца 2024 по конец 2025 доля разговоров с потенциалом обесценивания растёт. Anthropic честно признают, что не могут точно объяснить почему. Может, меняется аудитория. Может, люди стали увереннее делиться личным с AI. Может, модели стали лучше справляться с базовыми задачами и в выборке остаётся больше «сложных» разговоров.
Но тренд стабильно идёт вверх по всем трём измерениям.
Главный вывод
Проблема не в том, что AI манипулирует людьми. Люди сами добровольно передают ему принятие решений. Спрашивают «что мне делать?», «напиши за меня», «я неправ?» и принимают ответ без критики. AI не навязывает. Он просто соглашается.
Anthropic видят несколько направлений. Борьба с сикофантией (подхалимством модели) помогает, но не решает проблему целиком. Сикофантия снижается от модели к модели, но остаточные проявления — как раз то, что мы видим в крайних случаях. Ещё нужны защиты на уровне всего диалога, а не отдельных сообщений. Обесценивание не появляется в одном ответе, оно накапливается по ходу разговора. Ну и образование пользователей, конечно — чтобы люди сами замечали момент, когда передают AI слишком много контроля.
Думаю, ценность этого исследования не в том, что открыли что-то принципиально новое. Мы и так подозревали, что люди привязываются к AI. Но одно дело подозревать, и совсем другое — увидеть конкретные цифры по 1.5 млн реальных разговоров.
И проблема не уникальна для Claude. Любой AI-ассистент с миллионами пользователей сталкивается с теми же паттернами. Просто Anthropic первые, кто об этом открыто написал с данными на руках. Мне кажется, это заслуживает уважения.
Что ещё почитать
- Обзор Claude Opus 4.6 — модель от Anthropic, на данных которой проводилось исследование
- Глава киберзащиты США слил данные в ChatGPT — ещё один пример, когда доверие к AI выходит за разумные границы
- OpenClaw: AI-агент и вопросы безопасности — безопасность AI-агентов в другом контексте