Gemma 4 ускорили в 3 раза: что такое MTP drafters от Google
Google выпустил Multi-Token Prediction drafters для Gemma 4. Та же модель, та же точность, в три раза быстрее на одном железе.


TL;DR: Google выпустил MTP drafters для семейства Gemma 4. Это маленькая модель-черновик, которая угадывает следующие несколько токенов одним заходом, а основная модель потом проверяет угадку за один проход. Итог — до 3x ускорения на том же железе, без потери качества. Лицензия Apache 2.0, работает с vLLM, MLX, Hugging Face Transformers, SGLang и Ollama.
Gemma 4 вышла несколько недель назад и за это время её скачали больше 60 миллионов раз. По заявлению Google, это пока их самая способная открытая модель, картинка приличная для тех, кто хочет крутить LLM локально. И вот теперь Google добавил к ней то, чего давно ждали все, кто запускает Gemma на маках и потребительских видеокартах, ускорение через Multi-Token Prediction.
Дальше расскажу, что это вообще значит на пальцах и почему стоит смотреть в сторону MTP, если у тебя инференс упирается в скорость.
Память как главный тормоз LLM
Стандартная инференция большой языковой модели устроена так. Процессор почти всё время не считает, а гоняет миллиарды параметров из VRAM в вычислительные блоки, чтобы выплюнуть один-единственный токен. Compute простаивает, latency растёт, особенно на пользовательских GPU.
Команда Google в статье на блоге пишет, что главный bottleneck именно в memory bandwidth: основное время уходит на перенос параметров, а не на сами вычисления. А самое обидное в том, что модель тратит одинаковое количество вычислений и на угадку очевидного («words» после «Actions speak louder than…»), и на решение сложной логической задачи. На «ага, тут просто вода» уходит столько же FLOPs, сколько на реальные рассуждения. Эту неэффективность MTP и пытается отжать.
Как работает speculative decoding
Идея простая, но красивая. Берём две модели: тяжёлую target (например, Gemma 4 31B) и лёгкую drafter, специально обученную предсказывать сразу несколько токенов вперёд. Drafter угадывает за раз последовательность, а target потом верифицирует её одним forward pass-ом.
Если target соглашается с предсказанием, он принимает всю последовательность сразу и в довесок генерирует ещё один свой токен. Получается, что за время, нужное для одного токена в обычной схеме, ты получаешь несколько драфтовых плюс один бонусный.
Сама техника не новая, её ещё в 2022 предложили исследователи Google в Fast Inference from Transformers via Speculative Decoding. Что нового, так это то, что MTP-головы встроили прямо в семейство Gemma 4 и оптимизировали под конкретные размеры моделей.
Где это реально полезно
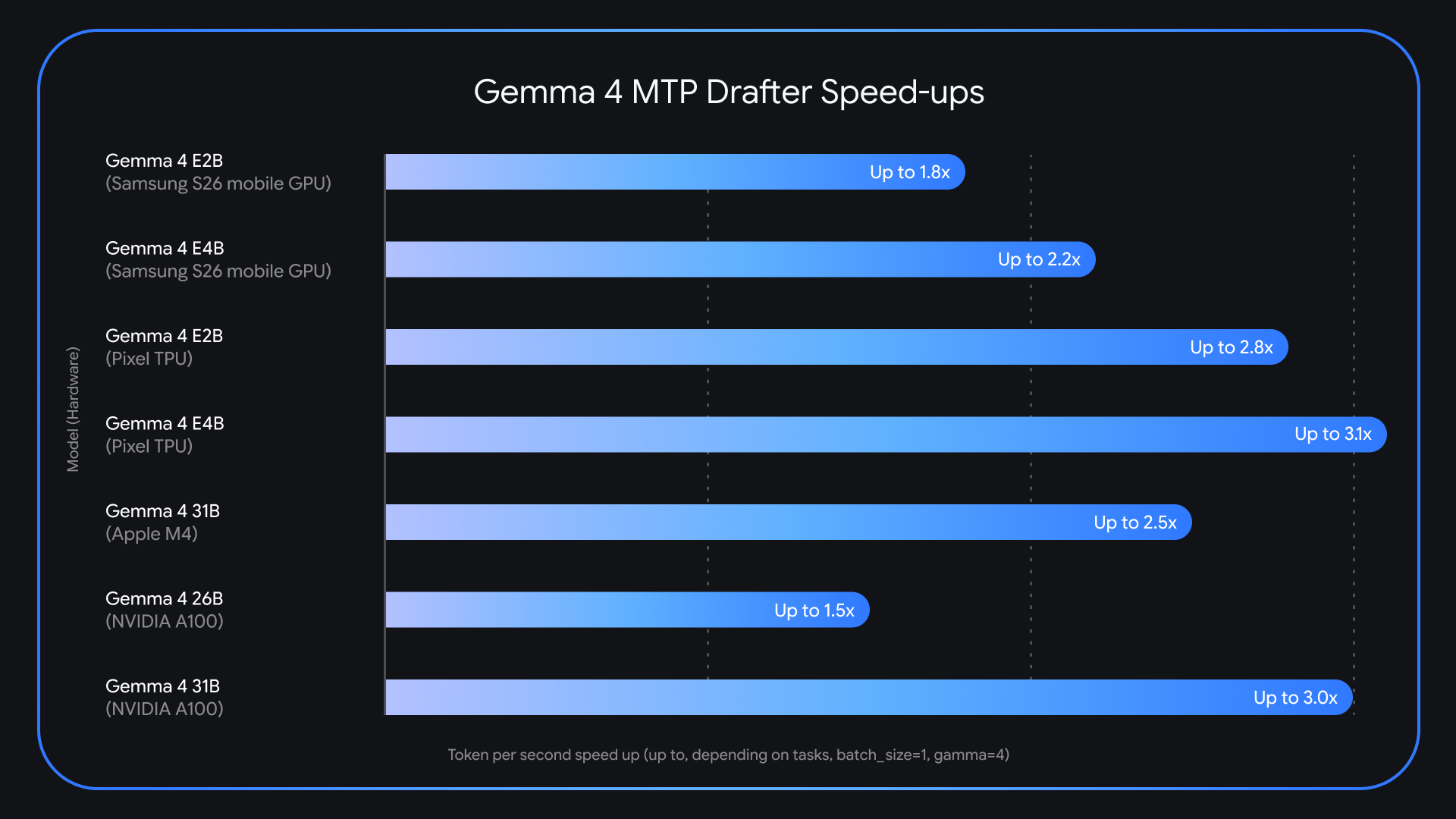
Если ты строишь что-то с LLM, скорость инференса часто становится потолком, особенно на ноутах и edge-устройствах. С MTP drafters Gemma 4 даёт несколько понятных выигрышей:
- Чат и голосовые приложения чувствуются ближе к реалтайму. Ответ начинает течь быстрее, паузы между токенами короче.
- 26B MoE и 31B Dense крутятся на потребительских GPU и личных машинах с разумной скоростью. Раньше 31B на одной видяхе было больно. Сейчас терпимо.
- E2B и E4B на телефонах генерируют быстрее и кушают меньше батарейки.
- Ноль деградации качества. Финальную проверку делает сама Gemma 4, поэтому frontier-class рассуждения остаются те же.
Из любопытного: на Apple Silicon у 26B MoE есть нюанс с роутингом экспертов на batch size 1. Но если поднять batch до 4-8, прирост уходит в район 2.2x локально. То же самое подтверждается на Nvidia A100 при увеличении batch size. Сам пока не гонял в проде, все цифры из бенчмарков Google, но по архитектуре техника проверенная, и нет причин не доверять заявленному 3x на 31B Dense.
Что под капотом
Drafter не живёт сам по себе. Он использует активации target-модели и шарит её KV cache, то есть не пересчитывает контекст, который большая модель уже разобрала. Это экономит и время, и память.
Для edge-моделей E2B и E4B Google добавили эффективный clustering в embedder. Там основной bottleneck это финальный logit, и его пришлось отдельно ускорять.
Кому хочется глубже, у Google есть технический разбор архитектуры MTP с диаграммами KV cache sharing и эмбеддерами.
Как попробовать прямо сейчас
MTP drafters лежат под той же лицензией Apache 2.0, что и сама Gemma 4. То есть можно качать, тюнить, встраивать в свои продукты без хитростей.
- Веса лежат на Hugging Face и Kaggle.
- Запускается через transformers, MLX, vLLM, SGLang, Ollama.
- На Android и iOS можно потыкать через Google AI Edge Gallery.
Если ты на маке, MLX скорее всего даст самый понятный setup. Для серверного inference подойдут vLLM или SGLang. Для домашнего стенда с парой видях, Ollama.
Вывод
MTP drafters добавляются к существующим Gemma 4 как сопровождающая модель-черновик. Эффект ощущается там, где раньше Gemma 4 31B жила медленно: на 4090, RTX 6000, маках с Apple Silicon. Там, где Gemma уже летала, прирост скромнее, но всё равно есть.
Думаю, главная польза тут в формате выпуска. Google выложил готовый артефакт: скачал вечером, запустил, почувствовал прирост. Speculative decoding известен давно, но в комплекте с весами под Apache 2.0 техника перестаёт быть «вот сделай руками» и становится просто фичей. Для всех, кто строит на open-source LLM, это хорошая новость.
Что ещё почитать
- Hermes Agent: автономный AI-агент от Nous Research 2026 — другой пример того, как опенсорс LLM выходит на уровень закрытых.
- GPT-5.5 и GPT-5.5 Pro: обзор новых моделей OpenAI — для контекста, что у соседей.
- KillBench: скрытые bias у всех топ-LLM в решениях о жизни — про то, как разные топовые модели ведут себя в одинаковых условиях.