Jina VLM — мультиязычная VLM на 2.4B параметров
Jina VLM — маленькая VLM от Jina AI, которая обгоняет Qwen3-VL и InternVL3 в мультиязычном понимании картинок. 2.4B параметров, работает на обычном GPU.


TL;DR: Jina VLM — vision-language модель на 2.4B параметров от Jina AI. Понимает картинки и текст на 29 языках, обгоняет Qwen3-VL-2B и InternVL3 в мультиязычных бенчмарках. Работает на обычном GPU, есть API и локальный запуск.
Jina VLM — open-source модель
Она смотрит на картинку и отвечает на вопросы о ней. Сделали в Jina AI (Берлин/Саннивейл), компания Han Xiao. До этого они были известны в основном эмбеддингами и реранкерами, так что VLM для них новая территория.
Вышла в декабре 2025. Внутри SigLIP2 как визуальный энкодер (449M параметров) и Qwen3-1.7B как языковой бэкбон. Между ними attention-pooling коннектор, который сжимает визуальные токены в 4 раза. Про это расскажу подробнее ниже, потому что это самое интересное в архитектуре.
Большинство 2B моделей хорошо работают на английском. Может быть на китайском. На этом всё. Jina VLM тренировали на 5 миллионах мультимодальных примеров и 12 миллиардах текстовых токенов. 29 языков, от арабского до вьетнамского. Примерно половина данных на английском, остальное размазано по другим языкам.
Быстрый старт
Есть три способа попробовать: через API, CLI или библиотеку Transformers.
Через API (самый быстрый)
Jina предоставляет OpenAI-совместимый API. Нужен API-ключ с jina.ai:
curl https://api-beta-vlm.jina.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $JINA_API_KEY" \
-d '{
"model": "jina-vlm",
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": "Опиши это изображение"},
{"type": "image_url", "image_url": {"url": "https://example.com/photo.jpg"}}
]
}]
}'
Формат стандартный, как у OpenAI. Кидаешь URL картинки или base64, получаешь ответ. Стриминг тоже есть ("stream": true).
Нюанс: API пока в бете (api-beta-vlm). Если сервис спит, вернёт 503. Ждёшь полминуты, повторяешь.
Локальный запуск через CLI
В репозитории на HuggingFace есть скрипт infer.py:
# Установка зависимостей
uv sync
# Для CUDA с FlashAttention2
uv sync --extra flash-attn
# Анализ одной картинки
python infer.py -i photo.jpg -p "Что на этом фото?"
# Сравнение двух картинок
python infer.py -i img1.jpg -i img2.jpg -p "Сравни эти изображения"
# Стриминг
python infer.py -i doc.png -p "О чём этот документ?" --stream
Через Transformers
from transformers import AutoModelForCausalLM, AutoProcessor
import torch
model = AutoModelForCausalLM.from_pretrained(
"jinaai/jina-vlm",
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto"
)
processor = AutoProcessor.from_pretrained(
"jinaai/jina-vlm", trust_remote_code=True
)
messages = [{"role": "user", "content": [
{"type": "image", "image": "document.png"},
{"type": "text", "text": "О чём этот документ?"}
]}]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True,
tokenize=True, return_dict=True, return_tensors="pt"
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=256, do_sample=False)
print(processor.decode(outputs[0], skip_special_tokens=True))
Ещё есть поддержка vLLM, если нужен продакшн-инференс.
Ключевые возможности
Мультиязычное понимание изображений
На MMMB (Multilingual Multimodal Benchmark) Jina VLM набирает 78.8. Qwen3-VL-2B — 75.0, InternVL3.5-2B — 74.6. Разница в 3-4 пункта, но для 2B моделей это заметный отрыв.
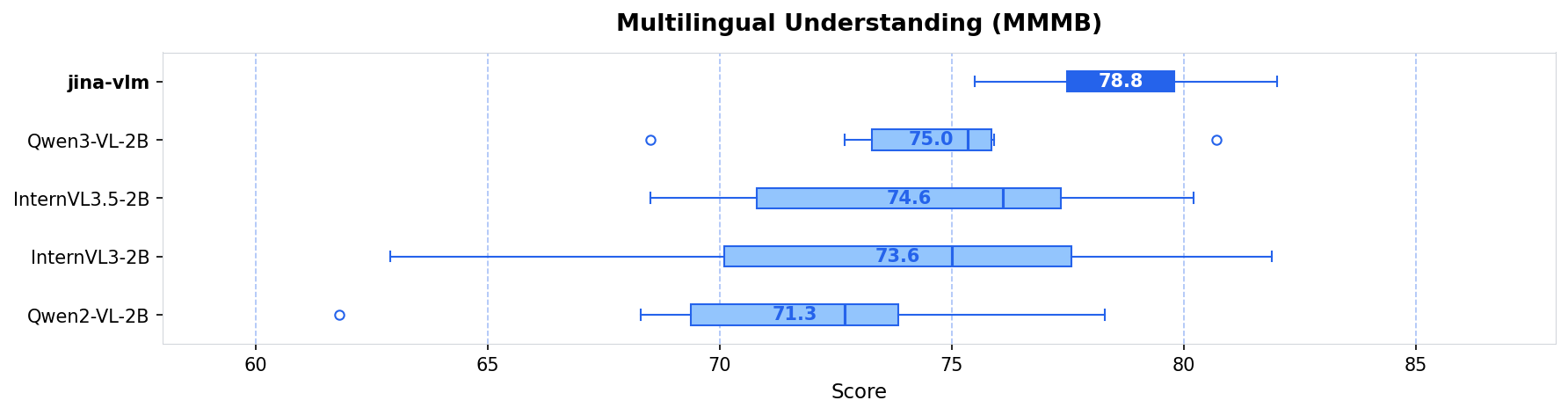
Тестировали на шести языках: арабский, китайский, английский, португальский, русский, турецкий. По русскому результат тоже хороший. Не могу сказать, что я проверял на сложных кейсах, но бенчмарки выглядят обещающе.
Работа с документами и OCR
DocVQA — 90.6. Qwen3-VL-2B тут сильнее (92.3), но разница небольшая. OCRBench — 778 из 1000.
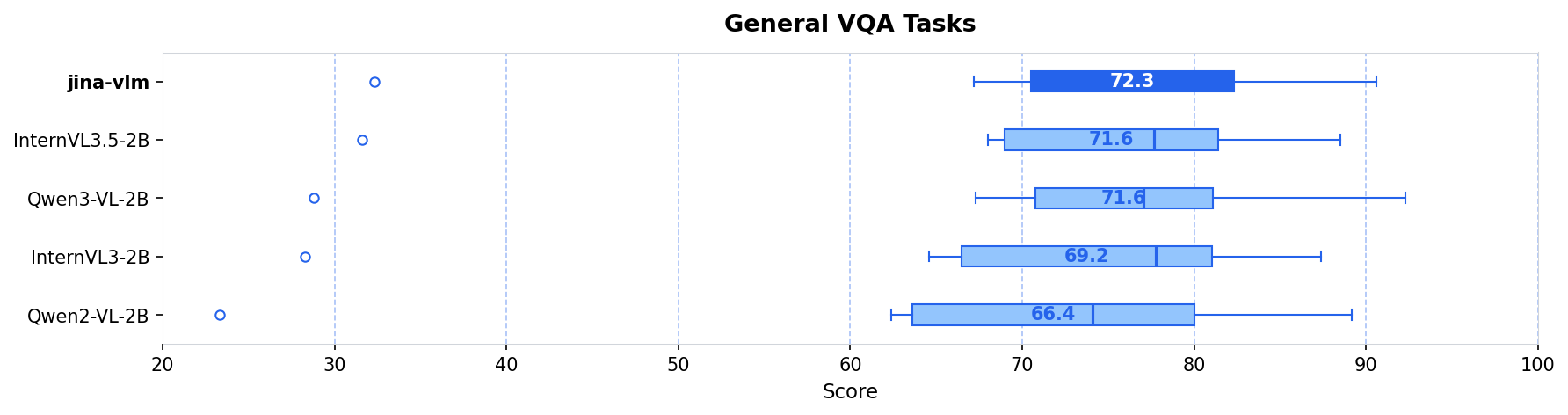
С диаграммами справляется хорошо (AI2D: 82.0), графики тоже норм (ChartQA: 81.9), текст на фотках читает (TextVQA: 83.2). Практически: скормил скан документа, задал вопрос, получил адекватный ответ.
Эффективность: attention-pooling
Обычная VLM прогоняет через языковую модель все визуальные токены. Их могут быть тысячи. Jina VLM использует attention-pooling коннектор: берёт 729 токенов на тайл и сжимает до 182. Четырёхкратное сокращение.

На практике это значит:
| Метрика | Без пулинга | С пулингом | Экономия |
|---|---|---|---|
| Визуальные токены (12 тайлов) | 9 477 | 2 366 | 4x |
| FLOPs на prefill | 27.2 TFLOPs | 6.9 TFLOPs | 3.9x |
| KV-cache память | 2.12 GB | 0.53 GB | 4x |
Меньше токенов, быстрее инференс, меньше памяти. На практике это значит, что модель влезает на обычную потребительскую GPU.
Сохранение текстовых способностей
Когда VLM учат работать с картинками, она часто забывает текст. Это называется catastrophic forgetting и это боль всех мультимодальных моделей. В Jina решили вопрос прямолинейно: на обоих этапах обучения добавили 15% чисто текстовых данных.
Помогло? Частично. По MMLU модель показывает 56.1, а базовый Qwen3-1.7B — 62.6. Просадка заметная, но не катастрофическая. На MMLU-Pro хуже: 30.3 против 46.4. Это цена за мультимодальность, и я не уверен, что её можно сильно снизить при 2B параметрах.
Сравнение с конкурентами
| Модель | Параметры | VQA Avg | MMMB | Multi. MMB | DocVQA | OCR |
|---|---|---|---|---|---|---|
| Jina VLM | 2.4B | 72.3 | 78.8 | 74.3 | 90.6 | 778 |
| Qwen3-VL-2B | 2.8B | 71.6 | 75.0 | 72.3 | 92.3 | 858 |
| InternVL3.5-2B | 2.2B | 71.6 | 74.6 | 70.9 | 88.5 | 836 |
| InternVL3-2B | 2.2B | 69.2 | 73.6 | 71.9 | 87.4 | 835 |
| Qwen2-VL-2B | 2.1B | 66.4 | 71.3 | 69.4 | 89.2 | 809 |
По средним VQA и мультиязычности Jina впереди. Qwen3-VL-2B выигрывает в работе с документами и OCR. InternVL3.5-2B где-то посередине.
Короче: нужен OCR на английском? Бери Qwen3-VL. Нужна мультиязычность? Jina VLM. Нужно всё сразу? Ну, тогда придётся брать что-то покрупнее 2B.
Тарифы
Лицензия CC BY-NC 4.0. Бесплатно для некоммерческого использования.
API пока в бете. Ключ получаешь на jina.ai. Конкретную стоимость за токен для VLM Jina пока не опубликовали, но у них общая система токенов для всех сервисов. Новым пользователям дают 10M бесплатных токенов, так что поэкспериментировать можно без платы.
Ещё модель доступна через маркетплейсы AWS, Azure и GCP.
Вердикт
Если тебе нужна VLM, которая понимает не только английский, и при этом влезает на обычную GPU, Jina VLM стоит попробовать. Для анализа документов и графиков на нескольких языках при 2B параметрах альтернатив сейчас немного.
Для чисто английского OCR я бы взял Qwen3-VL. Для коммерческого продакшна лицензия CC BY-NC может оказаться проблемой.
Больше всего мне понравился подход к эффективности. Attention-pooling с 4x сжатием, двухэтапное обучение с сохранением текстовых способностей. Видно, что в Jina AI думали не только про бенчмарки, но и про то, чтобы модель можно было реально запустить. Для экспериментов с мультимодальным AI на русском это пока один из лучших вариантов в весовой категории 2B.
Попробовать: Jina VLM
Что ещё почитать
- Mercury 2 — LLM на диффузии с 1000 токенов/сек — ещё один подход к ускорению инференса
- Обзор Gemini 3.1 Pro — мультимодальная модель от Google
- Обзор Claude Sonnet 4.6 — свежая модель Anthropic