Mercury 2 — LLM на диффузии с 1000 токенов/сек
Inception Labs показали Mercury 2 — языковую модель на основе диффузии, которая выдаёт больше 1000 токенов в секунду. Разбираемся, как это работает и зачем нужна.


TL;DR: Mercury 2 от Inception Labs — первая коммерческая LLM на основе диффузии, а не привычной авторегрессии. Генерирует 1009 токенов в секунду на NVIDIA Blackwell — это в 5 раз быстрее Claude Haiku и GPT-5 Mini. Стоит $0.25 за миллион входных токенов.
Все современные LLM работают одинаково: генерируют текст по одному токену, слева направо, как печатная машинка. Mercury 2 делает по-другому — модель уточняет сразу несколько токенов параллельно, больше похоже на редактора, который правит весь черновик целиком. Причём это не просто красивое сравнение — архитектура генерации у модели действительно другая.
Что такое диффузионная LLM?
Обычные модели — авторегрессионные. Каждый следующий токен зависит от предыдущего, поэтому генерация идёт строго последовательно. Хочешь быстрее — нужен либо более мощный GPU, либо более компактная модель. Ускорить сам процесс генерации при этом подходе физически сложно.
Mercury 2 использует диффузию — тот же принцип, что в генерации картинок (Stable Diffusion, DALL-E). Только вместо пикселей модель работает с токенами. Она берёт «шумный» черновик ответа и за несколько шагов уточняет его до финального текста, обрабатывая все позиции одновременно.
По данным Inception Labs, на GPU NVIDIA Blackwell Mercury 2 выдаёт 1009 токенов/сек. Для сравнения: Claude 4.5 Haiku Reasoning — около 89 токенов/сек, GPT-5 Mini — примерно 71 токен/сек.
Характеристики Mercury 2
| Параметр | Значение |
|---|---|
| Скорость | 1009 токенов/сек (NVIDIA Blackwell) |
| Цена (вход) | $0.25 / 1M токенов |
| Цена (выход) | $0.75 / 1M токенов |
| Контекст | 128K токенов |
| Reasoning | Настраиваемая глубина |
| Tool use | Нативная поддержка |
| JSON | Schema-aligned вывод |
| API | OpenAI-совместимый |
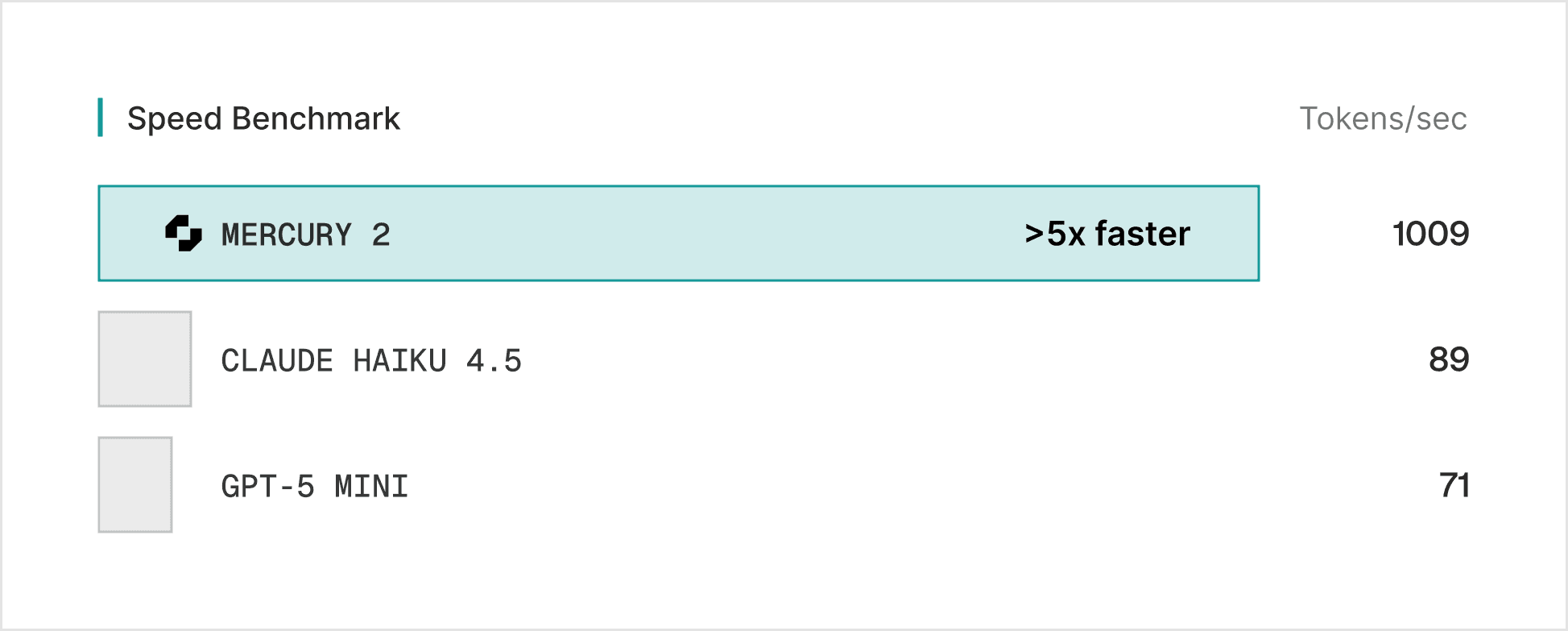
Цена тоже приятная. $0.25 за миллион входных токенов — это дешевле большинства speed-optimized моделей. Для задач, где нужно гонять тысячи запросов (агентские пайплайны, RAG, извлечение данных), экономия набегает существенная.
Качество — на уровне быстрых моделей
Скорость — это круто, но бесполезно, если модель отвечает ерунду. По бенчмаркам Mercury 2 конкурирует с Claude Haiku и GPT-5 Mini:
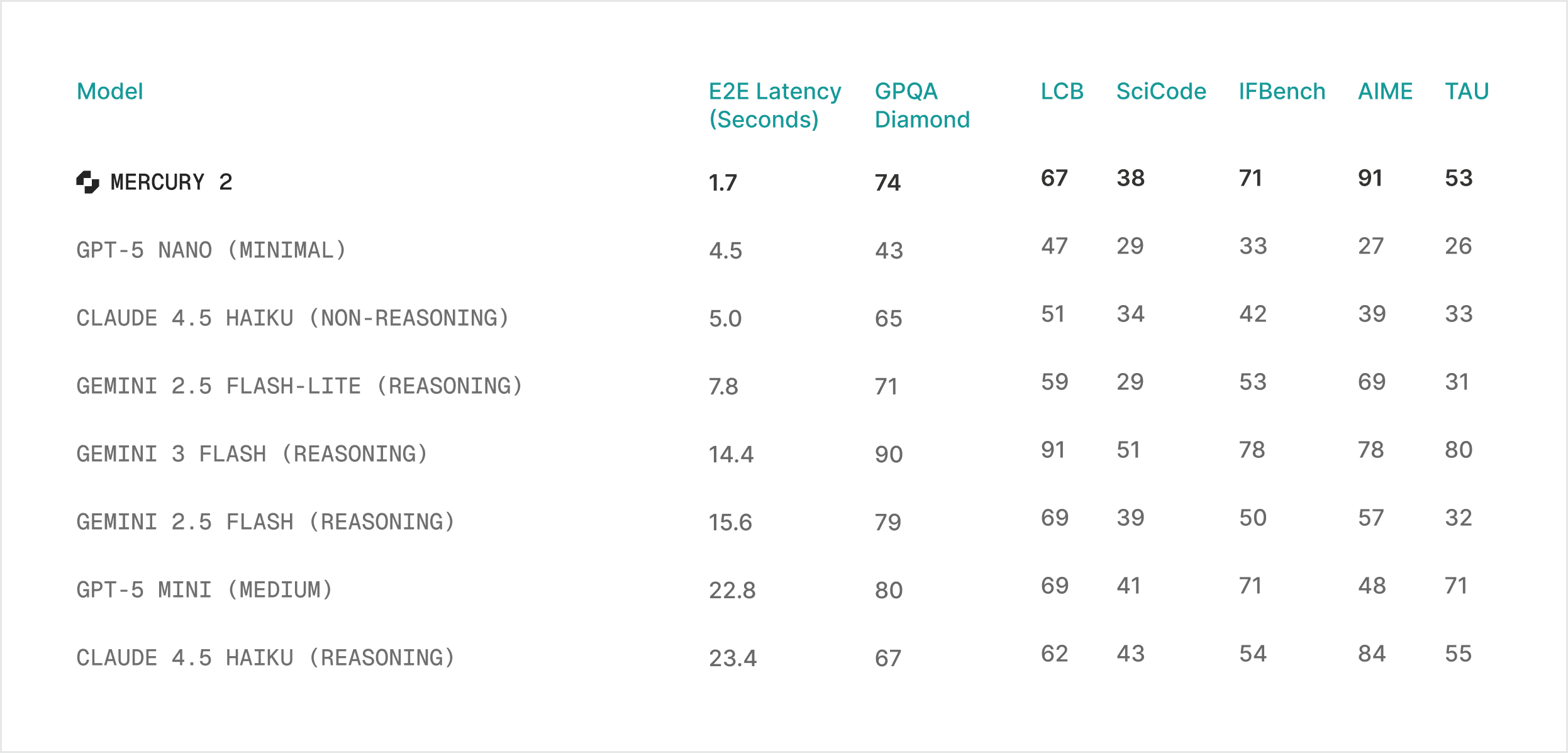
До уровня Claude Opus или GPT-5 модель не дотягивает, и это ожидаемо. Mercury 2 заточена под другое: скорость при достаточном качестве. Для глубокого рассуждения над сложной задачей — бери модели побольше.
Где это реально нужно?
Код и автодополнение
Для IDE-подсказок и автокомплита латентность критична. Макс Брунсфелд, сооснователь Zed, говорит: «Подсказки приходят достаточно быстро, чтобы казаться частью собственного мышления, а не чем-то, чего ждёшь». Разработчики Zed уже тестируют Mercury 2 в своём редакторе.
Агентские пайплайны
Когда AI-агент делает 20-50 вызовов модели за одну задачу, каждая секунда задержки множится. Сухинтан Сингх, CTO Skyvern, утверждает: «Mercury 2 минимум вдвое быстрее GPT-5.2, и для нас это меняет правила игры».
Голосовые интерфейсы
Если ты когда-нибудь разговаривал с голосовым ассистентом, который думает по две секунды над каждой репликой — знаешь, насколько это раздражает. Бюджет по латентности тут самый жёсткий: 300-500 мс, иначе диалог разваливается. Mercury 2 вписывается в эти рамки с reasoning-качеством, и это, пожалуй, самый впечатляющий кейс.
RAG и поисковые пайплайны
Когда поисковый пайплайн включает мультишаговый поиск, ранжирование и суммаризацию, задержки складываются на каждом шаге. Я сам сталкивался с тем, что добавление reasoning-модели в RAG-цепочку увеличивало время ответа втрое. С Mercury 2 такой шаг можно добавить, почти не теряя в скорости.
Интеграция — через OpenAI API
Mercury 2 совместима с OpenAI API, то есть можно подставить её в существующий стек без переписывания кода. Просто меняешь endpoint и model name — всё остальное работает как раньше.
Если нагрузка серьёзная, у Inception Labs есть программа для корпоративных клиентов — помогут протестировать под конкретные сценарии.
Чем это отличается от просто «быстрой модели»?
Тут важно понимать разницу. Обычно «быстрая модель» — это компактная авторегрессионная модель с меньшим количеством параметров. Она быстрее за счёт размера, но теряет в качестве пропорционально.
Mercury 2 быстрее за счёт другой архитектуры генерации. Диффузия позволяет масштабировать скорость без пропорциональной потери качества — потому что ты параллелишь не вычисления, а сам процесс декодирования. По сути, совсем другой принцип.
Думаю, если диффузионные LLM покажут себя стабильно — это может стать таким же сдвигом, как переход от RNN к трансформерам. Но пока Mercury 2 — первый коммерческий продукт такого типа, и мне не хватает данных, чтобы уверенно говорить о надёжности в долгосрочном продакшене.
Вывод
Mercury 2 — интересная штука. Первая серьёзная попытка уйти от авторегрессии в текстовой генерации, и результат впечатляет: 1000 токенов в секунду при адекватной цене и совместимости с OpenAI API.
Понятно, что уровня Opus или полноценного GPT-5 в сложных reasoning-задачах ждать не стоит. Но для агентских пайплайнов, кодинга и голосовых интерфейсов — мне сложно назвать что-то быстрее прямо сейчас.
Что ещё почитать
- Taalas HC1: AI-модель стала чипом — 17 000 токенов/сек — ещё один подход к ускорению: модель, вшитая прямо в кремний
- Nano Banana 2: качество Pro на скорости Flash — Google тоже гонит скорость, но остаётся в авторегрессии
- Claude Sonnet 4.6 — обзор новой модели Anthropic — для сравнения с reasoning-моделями побольше
FAQ
Чем Mercury 2 отличается от обычных LLM? Mercury 2 использует диффузионную архитектуру вместо авторегрессии. Модель генерирует несколько токенов параллельно, а не по одному последовательно. Это даёт пятикратное преимущество в скорости при сопоставимом качестве с Claude Haiku и GPT-5 Mini.
Можно ли использовать Mercury 2 вместо GPT или Claude? Зависит от задачи. Для сложного reasoning и длинных цепочек рассуждений лучше подойдут Opus или GPT-5. А вот для агентских пайплайнов, автокомплита кода, голосовых ассистентов и RAG-систем — Mercury 2 будет быстрее и дешевле.
Как подключить Mercury 2 к своему проекту? Mercury 2 совместима с OpenAI API. Меняешь endpoint и название модели в конфиге — и всё. Дополнительные SDK или библиотеки не нужны. Цена — $0.25 за миллион входных и $0.75 за миллион выходных токенов.