MiniMax M2.7: модель, которая сама себя обучала
Китайская MiniMax выпустила M2.7 — первую модель, которая активно участвовала в собственной эволюции. Бенчмарки на уровне топовых закрытых моделей.


TL;DR: MiniMax выпустила M2.7 — открытую модель, которая участвовала в собственном обучении через механизм self-evolution. По бенчмаркам догоняет Opus 4.6 и GPT-5.3: SWE-Pro 56.22%, VIBE-Pro 55.6%, а в OpenClaw-задачах показывает 62.7%.
Китайская MiniMax выпустила M2.7, и этот релиз интересен не очередным обновлением бенчмарков. Модель участвовала в собственной эволюции. Не в переносном смысле: M2.7 обновляла свою память, строила навыки для RL-экспериментов и улучшала свой harness на основе результатов. Цикл замкнулся.
Как работает self-evolution в MiniMax M2.7
MiniMax дала M2.7 задачу: построить research agent harness, который взаимодействует с разными исследовательскими группами внутри компании. Этот harness поддерживает data-пайплайны, тренировочные окружения, инфраструктуру и persistent memory.
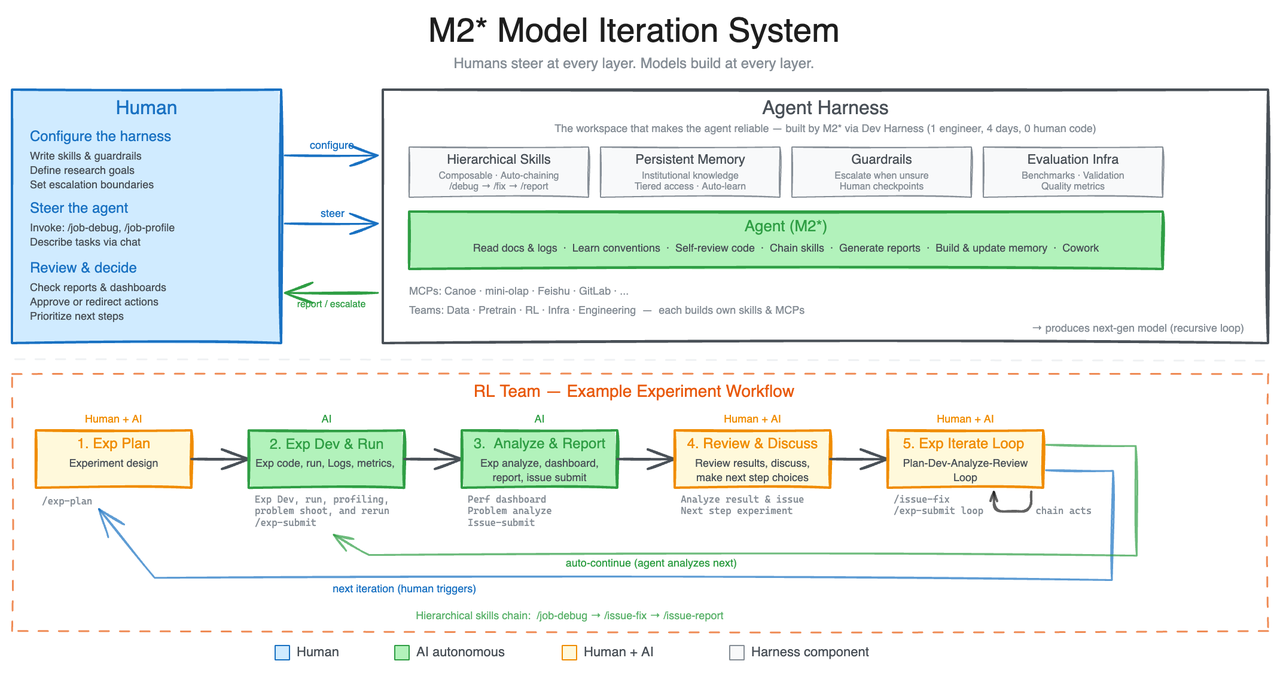
Исследователь из RL-команды обсуждает идею эксперимента с агентом. Агент помогает с обзором литературы, трекает спецификацию эксперимента, прокладывает data-пайплайны, запускает эксперименты. Во время работы сам мониторит прогресс, читает логи, дебажит, анализирует метрики, отправляет мерж-реквесты и прогоняет smoke-тесты. Раньше для этого нужна была координация нескольких исследователей из разных команд. Сейчас человек подключается только для ключевых решений.
По оценке MiniMax, M2.7 закрывает 30-50% рабочего процесса исследователя.
Ещё интереснее то, что модель рекурсивно улучшает свой harness. Собирает обратную связь, строит evaluation-сеты для внутренних задач, итерирует архитектуру, навыки и механизмы памяти.
Конкретный пример: M2.7 оптимизировала программерские способности модели на внутреннем scaffold. Полностью автономно, больше 100 раундов. Цикл: анализ фейлов → план изменений → правка кода scaffold → прогон eval → сравнение результатов → решение оставить или откатить. За это время модель нашла оптимальные комбинации sampling-параметров (temperature, frequency penalty, presence penalty), спроектировала более точные workflow-гайдлайны и добавила детекцию зацикливаний. Итог: +30% на внутренних eval-сетах.
MLE Bench: модель тренирует ML-модели
Чтобы проверить границы self-evolution, MiniMax запустила M2.7 на 22 ML-соревнованиях из MLE Bench Lite от OpenAI. Каждое соревнование работает на одной A30 GPU, но покрывает полный цикл ML-разработки.
Harness простой: три модуля (short-term memory, self-feedback, self-optimization). После каждого раунда агент генерирует markdown с памятью и делает self-criticism, который направляет следующую итерацию. Три запуска по 24 часа каждый.
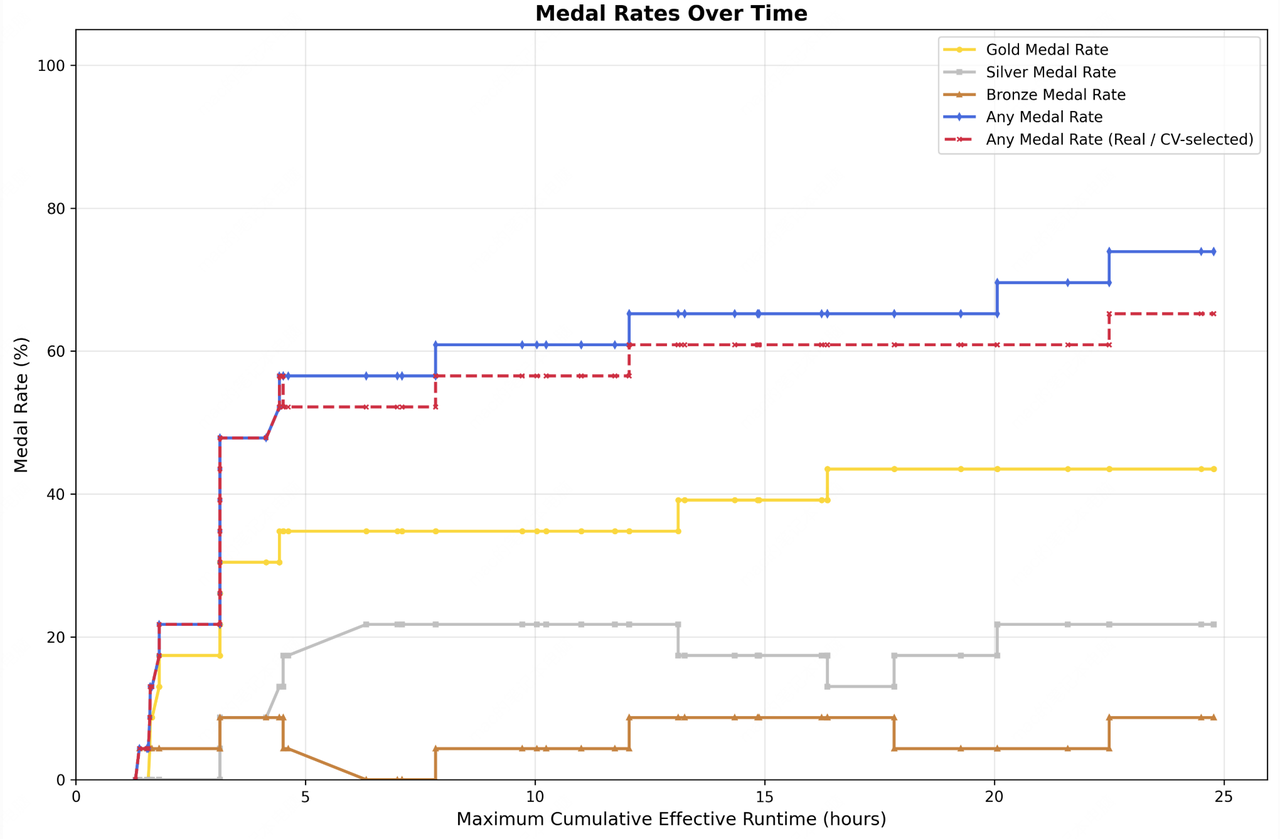
Результат лучшего запуска: 9 золотых, 5 серебряных, 1 бронзовая медаль. Средний medal rate по трём запускам — 66.6%, наравне с Gemini 3.1. Выше только Opus 4.6 (75.7%) и GPT-5.4 (71.2%). Для открытой модели, которую можно запустить локально, это очень близко к топу.
Бенчмарки MiniMax M2.7
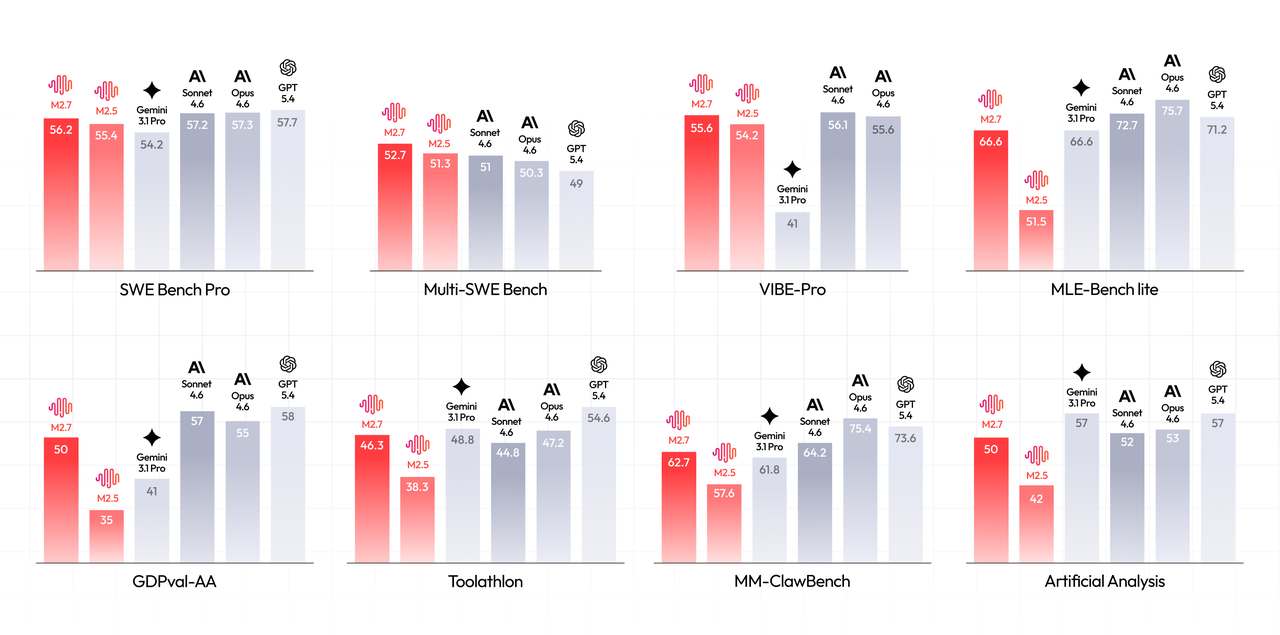
По программированию M2.7 вышла на уровень лучших закрытых моделей:
| Бенчмарк | M2.7 | Контекст |
|---|---|---|
| SWE-Pro | 56.22% | На уровне GPT-5.3-Codex |
| VIBE-Pro | 55.6% | Почти как Opus 4.6 |
| Terminal Bench 2 | 57.0% | Понимание сложных инженерных систем |
| SWE Multilingual | 76.5 | Многоязычное программирование |
| Multi SWE Bench | 52.7 | Мультирепозиторные задачи |
| NL2Repo | 39.8% | Генерация из описания на естественном языке |
В офисных задачах тоже хорошие цифры: ELO 1495 на GDPval-AA среди 45 моделей, уступает только Opus 4.6, Sonnet 4.6 и GPT-5.4. Модель умеет работать с Word, Excel и PPT: генерировать файлы по шаблонам, делать multi-round editing и выдавать готовые к правкам документы.
На Toolathon (точность работы с инструментами) M2.7 набрала 46.3%. На MM Claw (задачи из OpenClaw) — 62.7%, близко к Sonnet 4.6. При этом модель держит 97% compliance при работе с 40+ сложными навыками, каждый из которых больше 2000 токенов.
Agent Teams и дебаг в продакшне
Отдельная фича M2.7 — нативная поддержка Agent Teams, мультиагентной коллаборации. Это не промптинг с ролями. По словам MiniMax, модель интернализировала удержание роли, adversarial reasoning (оспаривание решений коллег-агентов), следование протоколам и поведенческую дифференциацию. Можно собрать команду агентов для разработки прототипа, где каждый отвечает за свою часть и может оспорить решения других.
MiniMax описывает кейс с дебагом в live-окружении: при алерте M2.7 коррелирует метрики мониторинга с таймлайнами деплоев, делает статистический анализ трейсов, подключается к базам для проверки гипотез, находит пропущенные миграции индексов и использует non-blocking index creation для «остановки кровотечения» до мерж-реквеста. По данным MiniMax, время восстановления инцидентов в нескольких случаях сократилось до трёх минут.
Если это работает так, как описано, для on-call инженеров это меняет многое. Связать мониторинг, код и базу данных в один пайплайн расследования вместо ручного переключения между десятком вкладок — это часы сэкономленного времени на каждом инциденте.
OpenRoom: AI за пределами текста
В M2.7 также подтянули character consistency и эмоциональный интеллект. На базе этого MiniMax построила OpenRoom — демо, где AI-взаимодействие происходит через Web GUI с визуальной обратной связью и сценами, а не через текстовый чат. Персонажи реагируют на окружение и инициируют действия сами.
Исходный код OpenRoom открыт (большая часть написана самой AI). Думаю, для тех, кто экспериментирует с game-подобными AI-интерфейсами, может быть полезной отправной точкой.
Где попробовать MiniMax M2.7
M2.7 доступна через MiniMax Agent, API Platform и Coding Plan для разработчиков. Модель также доступна через Ollama для локального запуска.
Открытая модель с цифрами на уровне Opus 4.6 и GPT-5.3, которую можно гонять локально через Ollama. Если работаешь с агентными пайплайнами или просто ищешь альтернативу закрытым API для кодинга, имеет смысл попробовать.
Что ещё почитать
- Топ-6 AI-агентов для кода в 2026 — сравнение M2.7 с другими вариантами для разработки
- Что реально умеет OpenClaw: 10 кейсов — платформа, где M2.7 показывает 62.7% на задачах из реальной жизни
- GLM-5-Turbo от Zhipu AI — ещё одна китайская модель с фокусом на агентные задачи
- Что такое agent harness — глоссарий: обвязка, которая превращает модель в агента
- 3 паттерна воркфлоу AI-агентов — архитектурные паттерны для сборки harness под M2.7