Qwen 3.6-Plus: Alibaba бросает вызов Claude в агентном кодинге
Alibaba выпустила Qwen 3.6-Plus с контекстом в 1 миллион токенов. Модель обходит Claude на Terminal-Bench и претендует на лидерство в агентном кодинге.


TL;DR: Alibaba выпустила Qwen 3.6-Plus с контекстом в 1 миллион токенов и фокусом на агентный кодинг. Модель обходит Claude Opus 4.5 на Terminal-Bench 2.0 (61.6 vs 59.3), но уступает ему на SWE-bench Verified (78.8 vs 80.9). Always-on reasoning, мультимодальность, совместимость с Claude Code и OpenClaw.
Что нового в Qwen 3.6-Plus
Контекстное окно выросло до 1 миллиона токенов — нативно, из коробки. У Qwen 3.5 было 256K с возможностью расширения до 1M, теперь миллион по умолчанию. По объёму контекста Qwen догнал Gemini 3 Pro.
Рассуждение (chain-of-thought) теперь включено всегда. В 3.5 был тогл thinking/non-thinking, здесь его убрали. Каждый ответ содержит цепочку рассуждений, которую можно проверить.
Ну и агентный кодинг — фронтенд, задачи уровня репозитория, терминальные операции. Alibaba называет это «transformative vibe coding experience».
Модель доступна через Alibaba Cloud Model Studio, поддерживает до 65 536 выходных токенов на ответ и совместима с протоколами OpenAI и Anthropic API.
Как Qwen 3.6-Plus показывает себя на бенчмарках
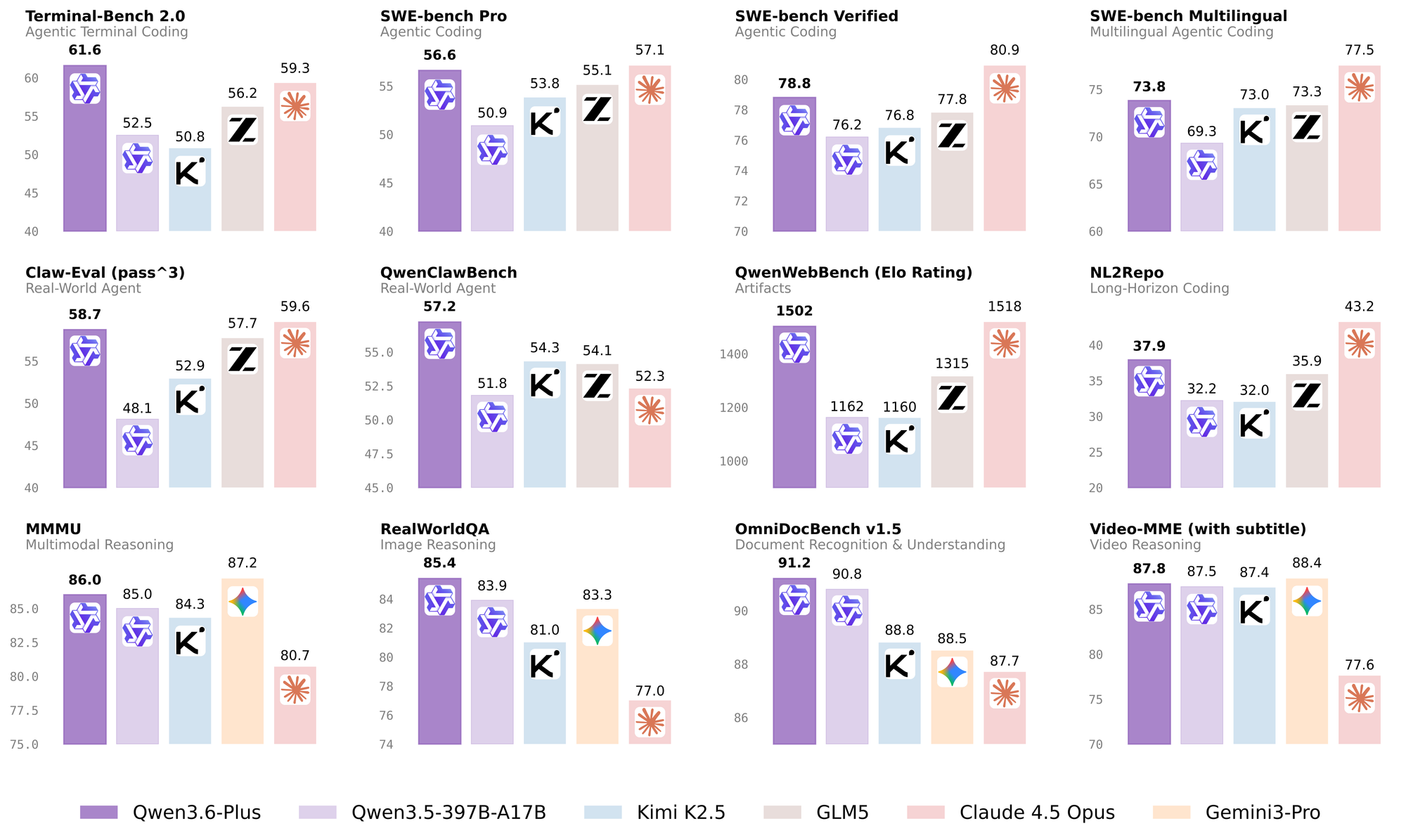
Вот что показывают цифры в сравнении с Claude Opus 4.5, Gemini 3 Pro, Kimi K2.5 и GLM-5.
Агентный кодинг
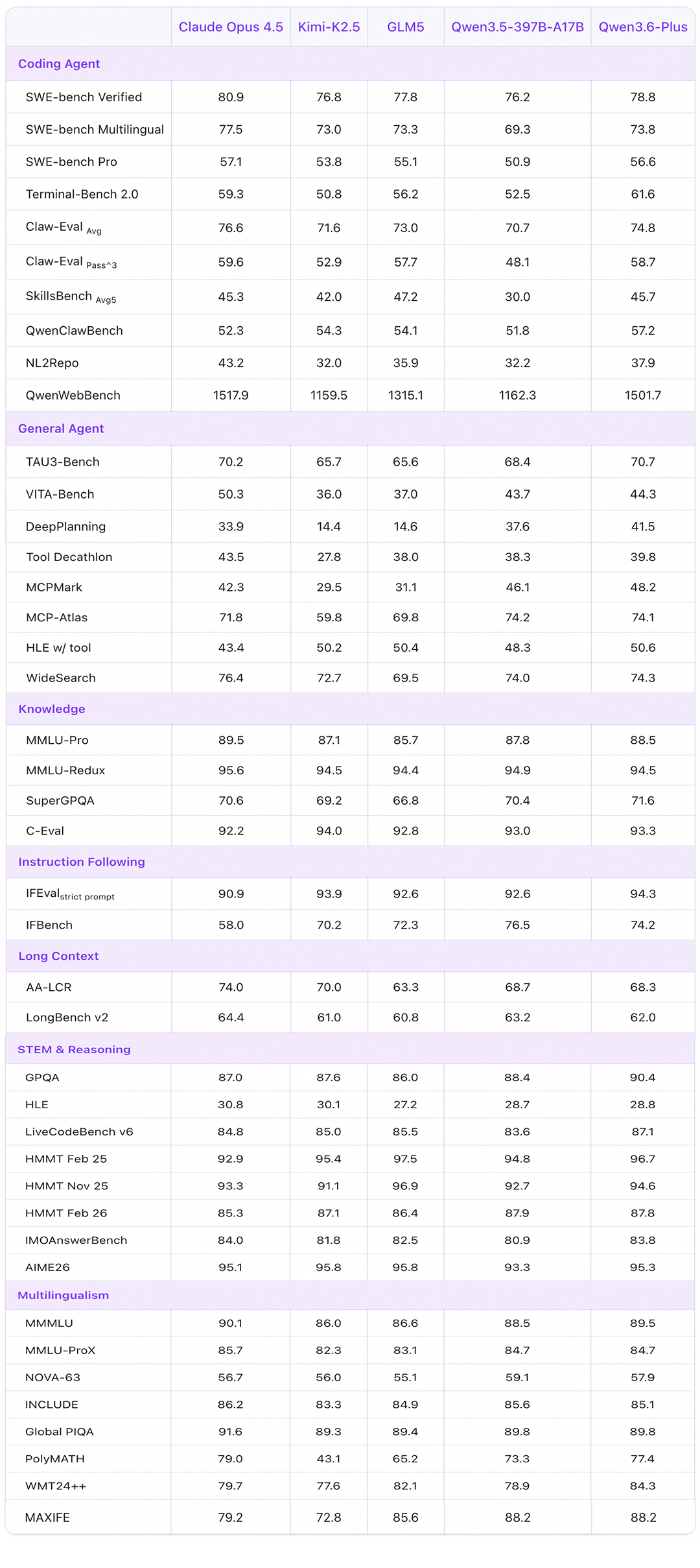
| Бенчмарк | Qwen 3.6-Plus | Claude Opus 4.5 | Gemini 3 Pro | GLM-5 |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 61.6 | 59.3 | — | 56.2 |
| SWE-bench Verified | 78.8 | 80.9 | — | 77.8 |
| SWE-bench Pro | 56.6 | 57.1 | — | 55.1 |
| SWE-bench Multilingual | 73.8 | — | 77.5 | 73.3 |
| Claw-Eval | 58.7 | 59.6 | — | 57.7 |
| NL2Repo | 37.9 | — | 43.2 | 35.9 |
Terminal-Bench 2.0 тут интереснее всего. Бенчмарк тестирует агентную работу в терминале, и Claude держал там первенство месяцами. Qwen 3.6-Plus его обошёл: 61.6 против 59.3.
На SWE-bench Verified картина другая. Claude Opus 4.5 впереди с 80.9 против 78.8 у Qwen. Разрыв в 2.1 балла — самый маленький в истории между любой моделью Qwen и Claude Opus. Год назад такое сравнение выглядело бы абсурдно.
NL2Repo (понимание репозиториев целиком) — тут лидирует Gemini 3 Pro с 43.2. Qwen на втором месте с 37.9. Для задач уровня «пойми весь репозиторий» Google пока впереди.
Мультимодальность
| Бенчмарк | Qwen 3.6-Plus | Claude Opus 4.5 | Gemini 3 Pro | Kimi K2.5 |
|---|---|---|---|---|
| OmniDocBench v1.5 | 91.2 | 87.7 | 87.7 | 88.8 |
| RealWorldQA | 85.4 | 77.0 | 83.3 | — |
| MMMU | 86.0 | — | 87.2 | 84.3 |
| Video-MME | 87.8 | 77.6 | 88.4 | 87.4 |
OmniDocBench — работа с документами, сканами, PDF. Qwen 3.6-Plus тут лидер с 91.2. Если работаешь с юридическими или финансовыми документами, где нужно парсить сложные PDF, это заметная разница.
RealWorldQA (рассуждения по картинкам из реального мира): 85.4 у Qwen против 77.0 у Claude. Разрыв заметный. Видео-понимание — Gemini 3 Pro чуть впереди (88.4 vs 87.8), но разница минимальная.
Скорость и практические нюансы
По данным BridgeBench, Qwen 3.6-Plus выдаёт 158 токенов в секунду — примерно в 3 раза быстрее Claude Opus 4.6 (93.5 tok/s). Но есть подвох: время до первого токена (TTFT) на бесплатном тире составляет 11.5 секунд. Если ты итерируешь код быстро, 11 секунд ожидания перед каждым ответом ломают ритм.
На платном API после GA эта проблема должна решиться, но пока стоит учитывать.
Что исправили по сравнению с Qwen 3.5
Главная жалоба на Qwen 3.5 — overthinking. Модель тратила кучу токенов на размышления даже по простым вопросам. Для агентных систем, где модель выполняет десятки мелких шагов, это было дорого и медленно.
Qwen 3.6-Plus решает эту проблему. Always-on reasoning теперь калиброван: модель быстрее приходит к выводам на простых задачах, тратит меньше токенов и стабильнее работает в многошаговых агентных сценариях. Ранние тестировщики отмечают меньше ретраев и снижение расхода токенов при тех же результатах.
То, что reasoning сделали always-on без переключателя — осознанный выбор. Каждый ответ можно проаудитировать. Для enterprise-задач, где нужно объяснять почему модель приняла конкретное решение, это полезно.
Как подключить Qwen 3.6-Plus
Модель совместима с OpenAI и Anthropic протоколами, так что интеграция простая.
Через Claude Code
export ANTHROPIC_MODEL="qwen3.6-plus"
export ANTHROPIC_SMALL_FAST_MODEL="qwen3.6-plus"
export ANTHROPIC_BASE_URL=https://dashscope-intl.aliyuncs.com/apps/anthropic
export ANTHROPIC_AUTH_TOKEN=<your_api_key>
claude
Через OpenClaw
curl -fsSL https://molt.bot/install.sh | bash
export DASHSCOPE_API_KEY=<your_api_key>
openclaw dashboard
Через Qwen Code
npm install -g @qwen-code/qwen-code@latest
qwen
У Qwen Code есть приятный бонус: OAuth-авторизация даёт 1000 бесплатных вызовов в день.
Также модель работает с Kilo Code, Cline и OpenCode. API-ключ можно получить в Alibaba Cloud Model Studio.
Визуальный кодинг и мультимодальные агенты
Qwen 3.6-Plus — нативная мультимодальная модель. Она генерирует фронтенд-код по скриншотам UI, дизайн-макетам и текстовым описаниям. На внутреннем бенчмарке QwenWebBench (качество генерации фронтенда) модель набрала Elo 1502 — на втором месте после Gemini 3 Pro (1518).
Для видео-понимания модель тоже прокачали: разбор временных зависимостей, анализ динамических изменений между кадрами, извлечение информации из видео. По Video-MME результат практически на уровне Gemini (87.8 vs 88.4).
Alibaba позиционирует это как шаг к «native multimodal agent», где модель не просто видит картинку, а понимает контекст и может что-то с этим сделать.
О чём стоит помнить перед использованием
Безопасность кода — слабое место. По данным BridgeBench, Qwen 3.6-Plus набрала 82.4 на Security Bench с 43.3% успехом на скрытых тестах. GPT-5.4 Mini — 87.3, Claude Sonnet 4.5 — 87.2. Если пишешь код с аутентификацией или платежами, стоит перепроверять.
Ещё один момент: 26.5% уровень фабрикации в рассуждениях. Примерно каждое четвёртое утверждение о поведении API или языковых конструкциях оказывается выдуманным. В агентных сценариях с минимальным контролем это накапливается.
Бесплатное превью собирает промпты и ответы для обучения модели. Не отправляй туда конфиденциальный код.
SLA. Превью без гарантий доступности. Спецификации могут измениться.
Вердикт
Qwen 3.6-Plus — пожалуй, самая сильная китайская модель для агентного кодинга на сегодня. Обойти Claude Opus 4.5 на Terminal-Bench 2.0 мало кому удавалось.
Если нужна модель для прототипирования с длинным контекстом, экспериментов с агентным кодингом или обработки документов, Qwen 3.6-Plus стоит попробовать. Бесплатный доступ убирает барьер для оценки, а 1M контекста — необходимость нарезки.
Для продакшена рановато. Нужен GA с платным тиром, нормальный TTFT и понятные условия по данным. Но как превью того, куда движется Alibaba, выглядит убедительно.
Alibaba обещает в ближайшие дни выложить open-source варианты меньшего размера. Так что следим.
Что ещё почитать
- GPT-5.4: computer use, tool search и 1M контекст — обзор конкурирующей модели OpenAI с тем же объёмом контекста
- GLM-5-Turbo: цены, сравнение и настройка OpenClaw — ещё одна китайская модель, которая претендует на лидерство
- Топ-6 AI-агентов для кода в 2026 — подборка инструментов, с которыми можно использовать Qwen 3.6-Plus
- 8 уровней агентного инжиниринга — фреймворк для понимания, на каком уровне находятся модели вроде Qwen