Qwen 3.5 — мультимодальный AI от Alibaba с 397B параметров
Alibaba выпустила Qwen 3.5 — мультимодальную MoE-модель с 397B параметров, из которых активны только 17B. Разбираю, что умеет и как выглядит на фоне конкурентов.


TL;DR: Alibaba выпустила Qwen 3.5 — мультимодальную модель с 397 миллиардами параметров, из которых активны только 17 миллиардов за один проход. Гибридная архитектура (линейное внимание + MoE) даёт скорость в 8.6 раз выше Qwen3-Max при сопоставимом качестве. На бенчмарках бьёт или догоняет GPT-5.2, Claude Opus 4.6 и Gemini-3 Pro, особенно в vision-задачах. Веса открыты.
Пока все обсуждают GPT-5.3 и Claude Opus 4.6, команда Qwen из Alibaba тихо выкатила модель, которая на ряде бенчмарков обходит обоих. Qwen 3.5-397B-A17B — это первая модель новой серии, и цифры впечатляют. Давай разберёмся, что внутри.
Что такое Qwen 3.5 и чем отличается от Qwen 3?
Главное отличие — Qwen 3.5 с самого начала мультимодальна. Обучали текст и картинки вместе с первого токена. Alibaba называет это native vision-language model.
Вторая большая штука — архитектура. Qwen 3.5 построена на Qwen3-Next, где совмещены два типа внимания:
- Gated Delta Networks для линейного внимания (быстрое и дешёвое)
- Gated Attention для сложных контекстов (классическое)
- Sparse MoE, где из 397 миллиардов параметров активируются только 17
На практике это значит, что модель знает столько же, сколько монстры на триллион параметров, но гонять её стоит как средненькую модель. Звучит как маркетинг, но бенчмарки вроде подтверждают.

По данным Alibaba, скорость декодирования Qwen 3.5-397B-A17B при контексте 32K в 8.6 раза выше, чем у Qwen3-Max. При 256K токенов контекста разница ещё больше: в 19 раз. Если сравнивать с Qwen3-235B-A22B, быстрее в 3.5 и 7.2 раза соответственно.
Ещё расширили поддержку языков со 119 до 201. Словарь вырос с 150K до 250K токенов, и это ускоряет кодирование и декодирование на 10-60% для большинства языков. Русский, само собой, поддерживается.
Бенчмарки: как Qwen 3.5 выглядит на фоне конкурентов?
Вот тут начинается самое интересное. Alibaba сравнила модель с GPT-5.2, Claude 4.5 Opus, Gemini-3 Pro и Kimi K2.5.
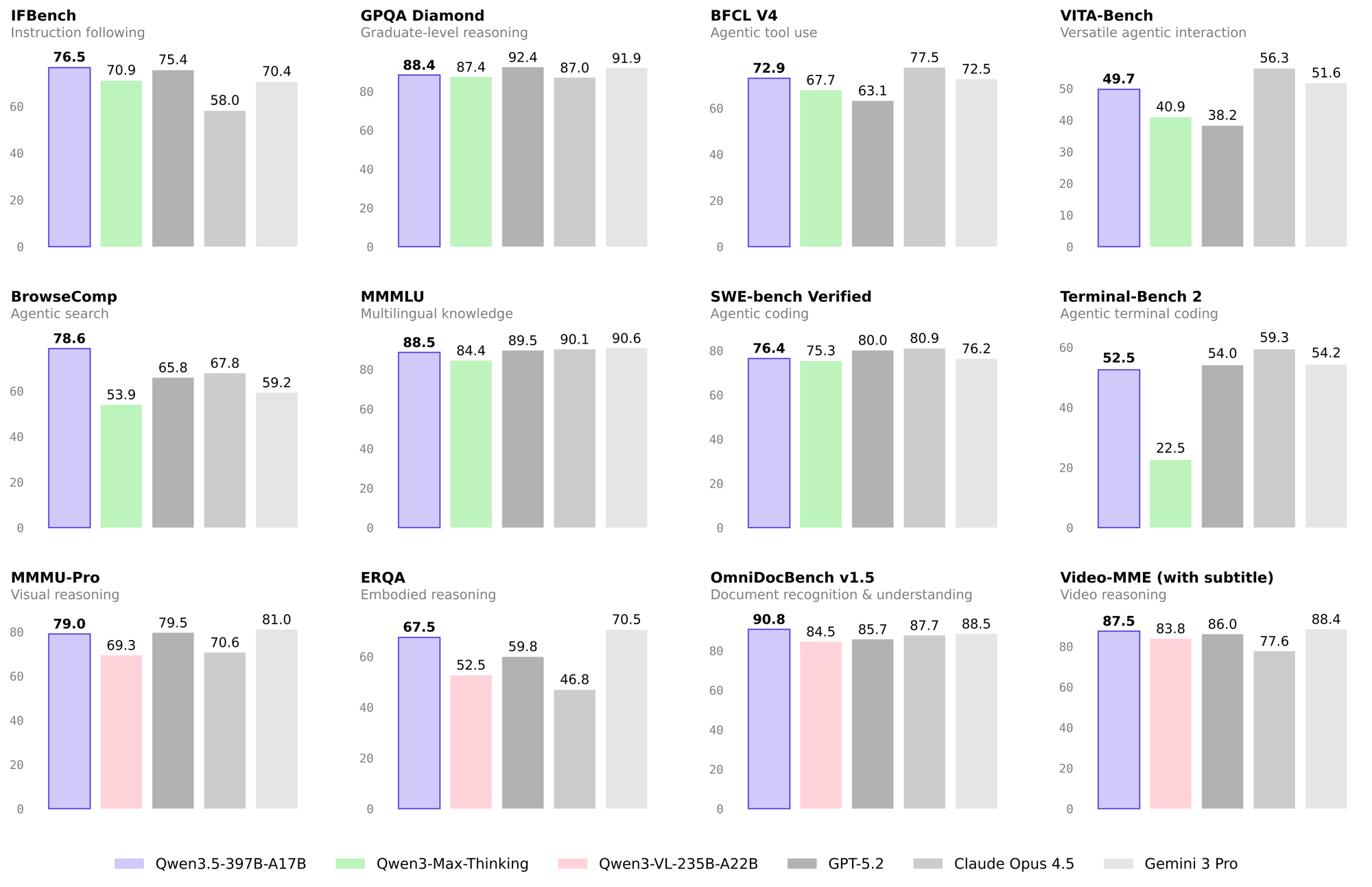
Текстовые задачи
Несколько цифр, которые бросаются в глаза:
| Бенчмарк | GPT-5.2 | Claude 4.5 Opus | Gemini-3 Pro | Qwen 3.5 |
|---|---|---|---|---|
| MMLU-Pro | 87.4 | 89.5 | 89.8 | 87.8 |
| IFBench | 75.4 | 58.0 | 70.4 | 76.5 |
| MultiChallenge | 57.9 | 54.2 | 64.2 | 67.6 |
| BFCL-V4 (агенты) | 63.1 | 77.5 | 72.5 | 72.9 |
| TAU2-Bench | 87.1 | 91.6 | 85.4 | 86.7 |
| BrowseComp | 65.8 | 67.8 | 59.2 | 69.0/78.6 |
| SWE-bench Verified | 80.0 | 80.9 | 76.2 | 76.4 |
По следованию инструкциям (IFBench, MultiChallenge) Qwen 3.5 вырвалась вперёд, обходит и GPT-5.2, и Claude, и Gemini. В агентских задачах показывает крепкие результаты, хотя Claude Opus 4.6 пока лидирует в BFCL-V4 и TAU2-Bench.
В поисковых задачах (BrowseComp) Qwen 3.5 набирает 78.6 с продвинутой стратегией. Это лучший результат среди всех протестированных моделей.
Кодинг на уровне конкурентов: SWE-bench 76.4 при 80.0 у GPT-5.2 и 80.9 у Claude. Не лидер, но очень близко. И это при том, что активных параметров в 4-5 раз меньше.
Vision-задачи — тут Qwen 3.5 сильнее всего
| Бенчмарк | GPT-5.2 | Claude 4.5 Opus | Gemini-3 Pro | Qwen 3.5 |
|---|---|---|---|---|
| MathVision | 83.0 | 74.3 | 86.6 | 88.6 |
| ZEROBench | 9 | 3 | 10 | 12 |
| ZEROBench_sub | 33.2 | 28.4 | 39.0 | 41.0 |
| BabyVision | 34.4 | 14.2 | 49.7 | 52.3 |
| OCRBench | 80.7 | 85.8 | 90.4 | 93.1 |
| CountBench | 91.9 | 90.6 | 97.3 | 97.2 |
| HallusionBench | 65.2 | 64.1 | 68.6 | 71.4 |
| LingoQA | 68.8 | 78.8 | 72.8 | 81.6 |
Нативная мультимодальность тут реально работает. MathVision 88.6, лучший результат среди всех моделей в тесте. ZEROBench (считается одним из самых сложных visual бенчмарков) тоже первое место: 12 баллов против 10 у Gemini и 9 у GPT-5.2. OCR-задачи — 93.1, опять выше всех.
Я, если честно, не ожидал такого от open-weight модели. Обычно открытые модели проигрывают закрытым именно в мультимодальных задачах. Тут Alibaba этот паттерн сломала. Хотя, конечно, надо делать скидку на то, что бенчмарки они публикуют сами, а независимых тестов пока мало.
Агентские способности: масштабирование через RL
Отдельно хочу выделить подход к обучению агентских способностей. Команда Qwen масштабировала reinforcement learning не на конкретные бенчмарки, а на разнообразие и сложность RL-окружений. Идея в том, что если модель учится в тысячах разных ситуаций, она лучше обобщает.
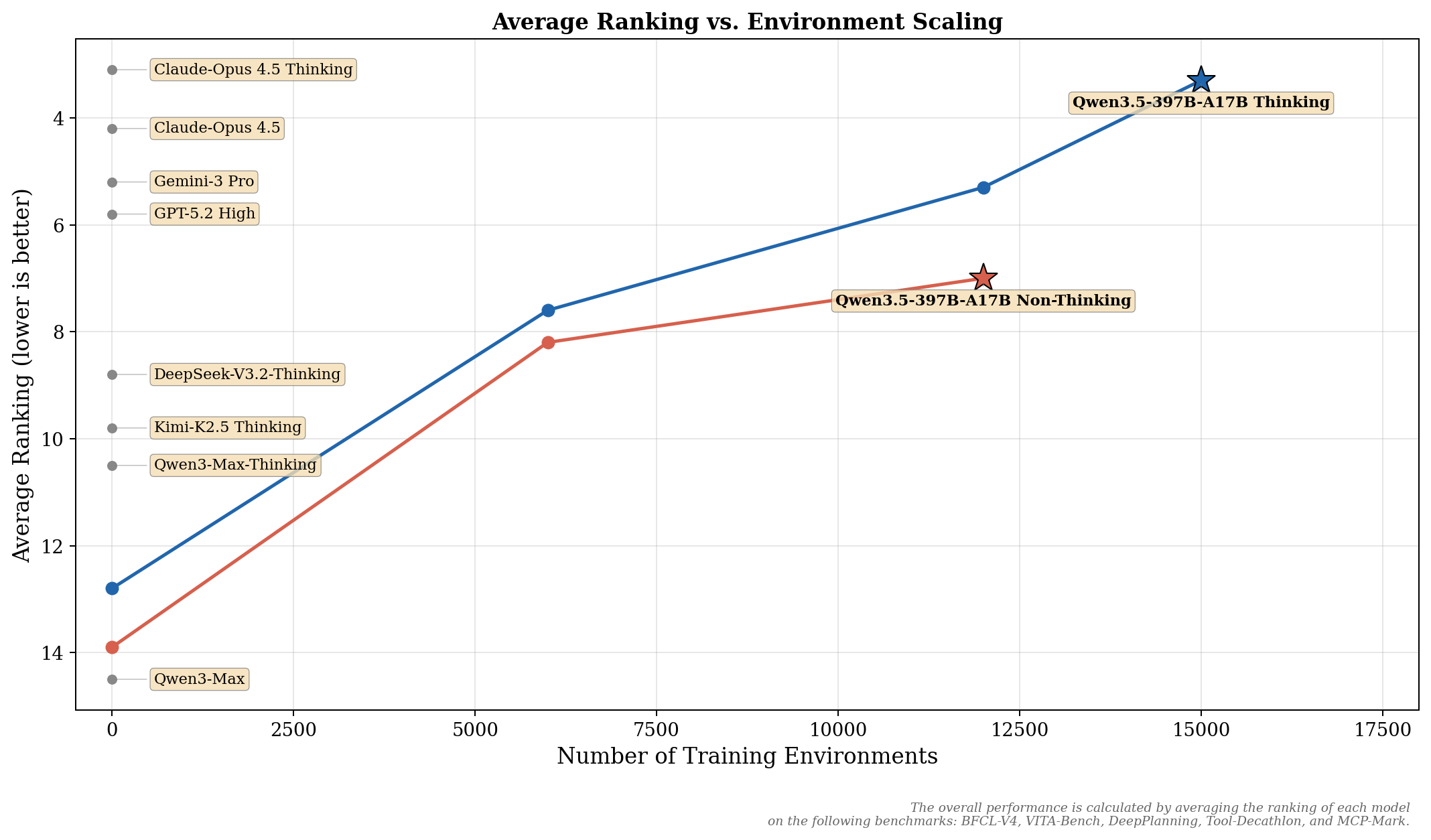
Результат на агентских бенчмарках пока не лидерский: DeepPlanning 34.3 (GPT-5.2 набирает 44.6, хотя Claude только 33.9), MCP-Mark 46.1 (GPT-5.2 тут 57.5, Claude 42.3). Но сам подход через масштабирование окружений, а не натаскивание на конкретные тесты, мне кажется более правильным в долгосрочной перспективе.
Инфраструктура и скорость обучения
Для тех, кому интересна техническая начинка. Alibaba сделала гетерогенный пайплайн, где параллелизм настроен отдельно для vision и language частей модели. Это логично, потому что нагрузка на эти компоненты разная.
Ещё перевели всё на нативный FP8: низкая точность для активаций, маршрутизации MoE и GEMM. Результат — примерно 50% экономии памяти и 10%+ прирост скорости. Для RL-обучения построили асинхронный фреймворк с полностью разделёнными training и inference, что дало ускорение в 3-5 раз.
Вообще, мне нравится, что Alibaba вкладывается в инженерию запуска. Модель, которую дорого гонять, никому не нужна.
Где попробовать Qwen 3.5?
Самый простой вариант — зайти на Qwen Chat. Там три режима: Auto (модель сама решает, думать ей или нет, и может использовать инструменты), Thinking (глубокие рассуждения для сложных задач) и Fast (мгновенные ответы без раздумий).
Для разработчиков есть Alibaba Cloud ModelStudio с моделью Qwen3.5-Plus. Контекст 1M токенов, встроенные инструменты. API совместим с OpenAI SDK, так что подключить к существующему проекту минут за пять.
Ну и веса лежат на Hugging Face, если хочешь запустить у себя.
Что умеет как агент: демо
Команда показала несколько демо, и пара из них меня зацепила.
Первое — visual coding. Модель обрабатывает до 2 часов видео (благодаря контексту в 1M токенов) и может превратить нарисованный от руки макет UI в рабочий код. Или посмотреть запись геймплея и написать клон игры на HTML.
Второе — thinking with images. Модель не просто смотрит на картинку. Она может запустить code interpreter в процессе рассуждения. В одном из демо ей показали лабиринт, и она написала BFS-алгоритм на Python, нашла кратчайший путь и нарисовала его поверх изображения.
Ещё показали GUI-агента, который управляет смартфонами и компьютерами автономно, и пространственный интеллект для понимания сцен автовождения. Но эти демо менее впечатляющие — похожие штуки показывали и Claude, и Gemini.
Вывод
Qwen 3.5 меня удивила. Vision-бенчмарки на первом месте, текстовые — на уровне GPT-5.2 и Claude Opus 4.6, а активных параметров при этом в разы меньше. И всё это в открытых весах.
Думаю, главная история тут даже не про конкретные цифры (на верхушке все примерно одинаковые), а про подход. 17 миллиардов активных параметров при качестве модели на 397 миллиардов. Вот по этому пути, мне кажется, пойдёт вся индустрия.
Если работаешь с мультимодальными задачами или строишь агентов, попробуй. Особенно если платишь за инференс из своего кармана.
Что ещё почитать
- GPT-5.3 Codex vs Claude Opus 4.6 — сравнение двух главных конкурентов
- Kimi K2.5 — китайский open-source с роем из 100 агентов — ещё одна сильная модель из Азии
- GLM-5 от Zhipu — лучшая open-source модель 2026 — китайский конкурент в open-source сегменте
- Qwen3-Coder-Next — маленькая модель, которая кодит как большая — предыдущая модель от Qwen для кодинга
FAQ
Qwen 3.5 — open-source или нет?
Qwen 3.5 — open-weight модель. Веса доступны на Hugging Face и ModelScope, но лицензия может ограничивать коммерческое использование. Это не полный open-source, где открыт весь код обучения, но для большинства задач этого достаточно.
Сколько нужно GPU для запуска Qwen 3.5 локально?
Полная модель на 397B параметров требует серьёзного железа — минимум 8 GPU уровня A100/H100. Но активных параметров всего 17B, поэтому можно ожидать квантизованные версии, которые запустятся на более скромном оборудовании.
Чем Qwen 3.5 лучше GPT-5.2 и Claude Opus 4.6?
В vision-задачах Qwen 3.5 лидирует: MathVision 88.6, ZEROBench 12, OCRBench 93.1. В текстовых задачах — на уровне конкурентов. Главное преимущество — стоимость: активных параметров в разы меньше, а качество сопоставимое.
Поддерживает ли Qwen 3.5 русский язык?
Да. Модель поддерживает 201 язык и диалект, включая русский. Словарь расширен до 250K токенов, что улучшает эффективность работы с неанглийскими языками.