8 уровней агентного инжиниринга
Bassim Eledath предложил фреймворк из 8 уровней агентного инжиниринга. От автокомплита в Copilot до автономных команд агентов, которые координируются между собой без человека.

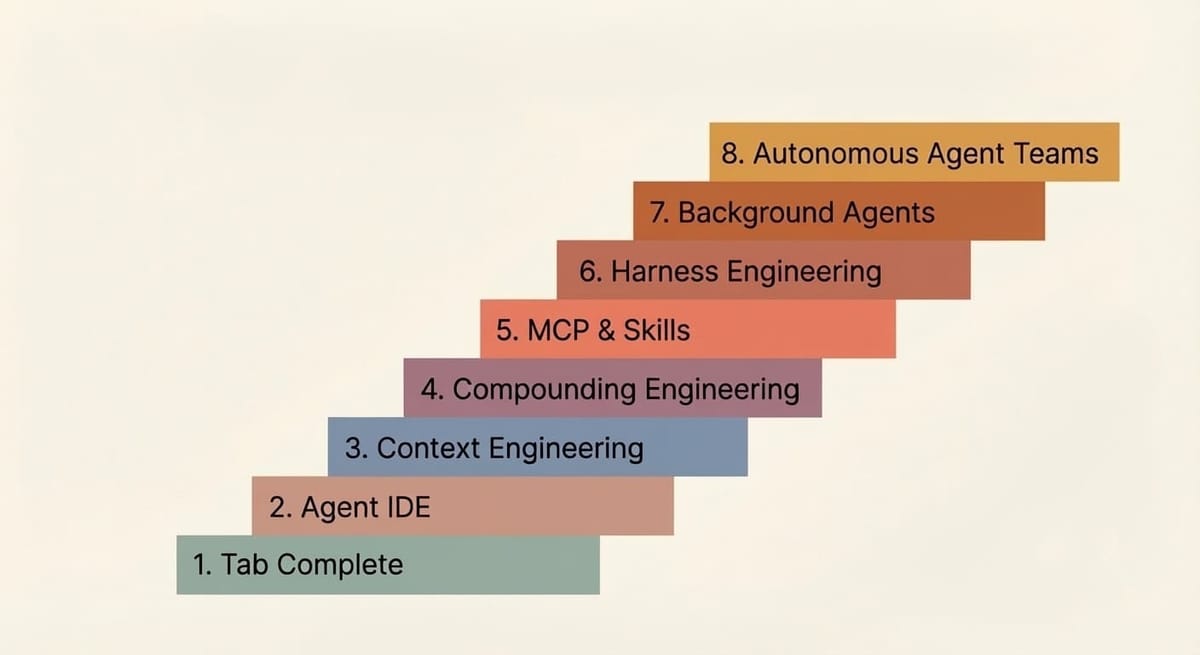
TL;DR: Bassim Eledath предложил фреймворк из 8 уровней агентного инжиниринга. От tab-complete в Copilot до автономных команд агентов, которые координируются между собой без человека. Большинство разработчиков застряли на уровнях 3-4, а реальный рывок в продуктивности начинается с пятого.
Модели умеют писать код лучше, чем большинство из нас умеет ими пользоваться. Команда Anthropic выкатывает Cowork за 10 дней, а другая команда с теми же моделями не может допилить прототип. Разница не в моделях. Разница в том, насколько команда научилась с ними работать.
Bassim Eledath разложил этот путь на 8 уровней. Не как строгую лестницу (можно перескакивать), а как ориентир: где ты сейчас и куда двигаться.
Уровни 1-2: автокомплит и агентные IDE
Начиналось всё с Copilot и tab-complete. Нажал Tab, получил автодополнение. Это хорошо работало для опытных разработчиков, которые умели выстроить скелет кода, а AI заполнял пробелы.
Потом пришли агентные IDE вроде Cursor. Чат подключили к кодовой базе, мультифайловые правки стали проще. Но потолок был один и тот же: контекст. Модель помогала только с тем, что видела. И часто видела не то, что нужно, или слишком много лишнего.
На этом же уровне многие начинают экспериментировать с plan mode: описываешь задачу, агент строит пошаговый план, ты его корректируешь, потом запускаешь выполнение. Работает, но дальше зависимость от ручного планирования будет снижаться.
Уровень 3: Context engineering
Buzz-фраза 2025 года. Context engineering стал важен, когда модели научились хорошо следовать инструкциям при условии, что контекст чистый. Шумный контекст был так же плох, как недостаточный. Мантра того периода: «Каждый токен должен бороться за своё место в промпте».
На практике context engineering затрагивает больше, чем кажется. Это файлы правил (.cursorrules, CLAUDE.md). Описания инструментов, по которым модель решает, какой вызвать. Управление историей диалога, чтобы агент не терял нить через десять шагов. Фильтрация инструментов на каждом шаге, потому что слишком большой выбор перегружает модель так же, как перегружает людей.
Сейчас о context engineering говорят меньше. Модели стали терпимее к шуму, контекстные окна выросли. Но контекст по-прежнему имеет значение в нескольких сценариях:
- Маленькие модели чувствительнее к контексту. В голосовых приложениях используют модели поменьше, а размер контекста напрямую влияет на задержку.
- Тяжёлые инструменты. MCP вроде Playwright и картинки сжигают токены. В Claude Code можно влететь в compact session гораздо быстрее, чем ожидаешь.
- Агент с десятками инструментов тратит больше токенов на парсинг схем, чем на полезную работу.
Главный сдвиг: фокус переместился с «убрать лишний контекст» на «доставить нужный контекст в нужный момент».
Уровень 4: Compounding engineering
Context engineering улучшает текущую сессию. Compounding engineering улучшает каждую следующую. Концепцию популяризировал Kieran Klaassen, и для многих это стало поворотным моментом: «вайб-кодинг» оказался способен на большее, чем просто прототипирование.
Цикл простой: планируй, делегируй, оценивай, кодифицируй. Последний шаг делает систему кумулятивной. LLM не помнят ничего между сессиями. Если модель вчера добавила зависимость, которую ты удалил, завтра она сделает то же самое. Если ты не записал правило.
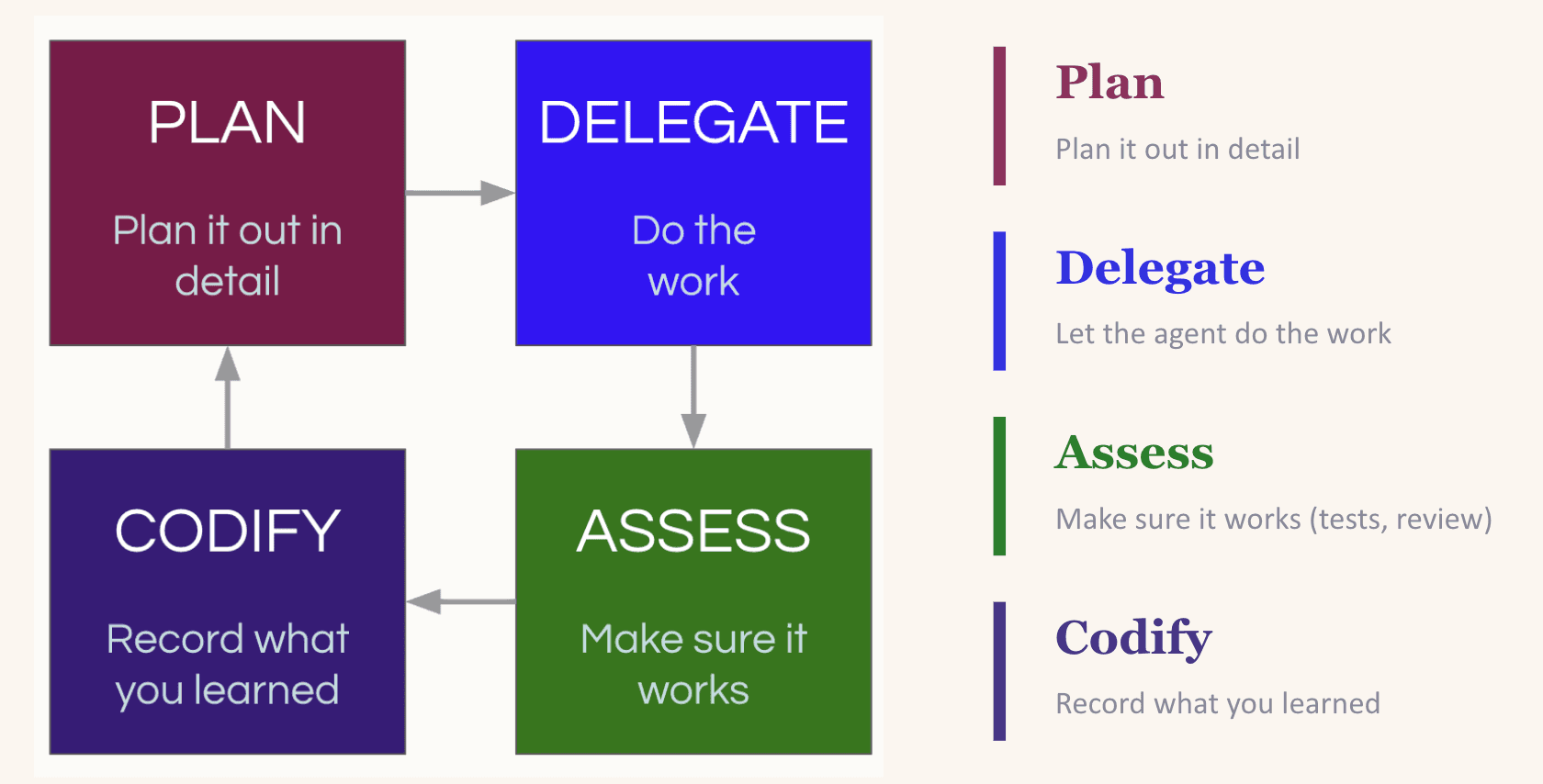
Самый распространённый способ кодификации: обновлять CLAUDE.md (или аналогичный файл правил), чтобы урок был встроен в каждую будущую сессию. Но тут есть ловушка. Инстинкт записывать всё подряд приводит к тому, что файл правил раздувается, а слишком много инструкций работает так же плохо, как их отсутствие. Лучший подход: создать среду, где LLM может сам находить нужный контекст. Например, поддерживать актуальную папку docs/.
Люди, которые практикуют compounding engineering, думают о контексте инстинктивно. Когда LLM ошибается, они сначала проверяют, какого контекста не хватило, а не обвиняют модель. Этот инстинкт открывает дверь к уровням 5-8.
Уровень 5: MCP и навыки
Уровни 3 и 4 решают задачу контекста. Уровень 5 решает задачу возможностей. MCP-серверы и пользовательские навыки дают LLM доступ к базе данных, API, CI-пайплайну, дизайн-системе, Playwright для тестирования, Slack для уведомлений. Модель больше не просто думает о коде. Она действует.
Bassim приводит пример: его команда использует общий навык для ревью PR, который запускает субагентов в зависимости от типа изменений. Один проверяет интеграцию с базой данных. Другой ищет переусложнение. Третий валидирует формат промптов. Плюс линтеры и Ruff.
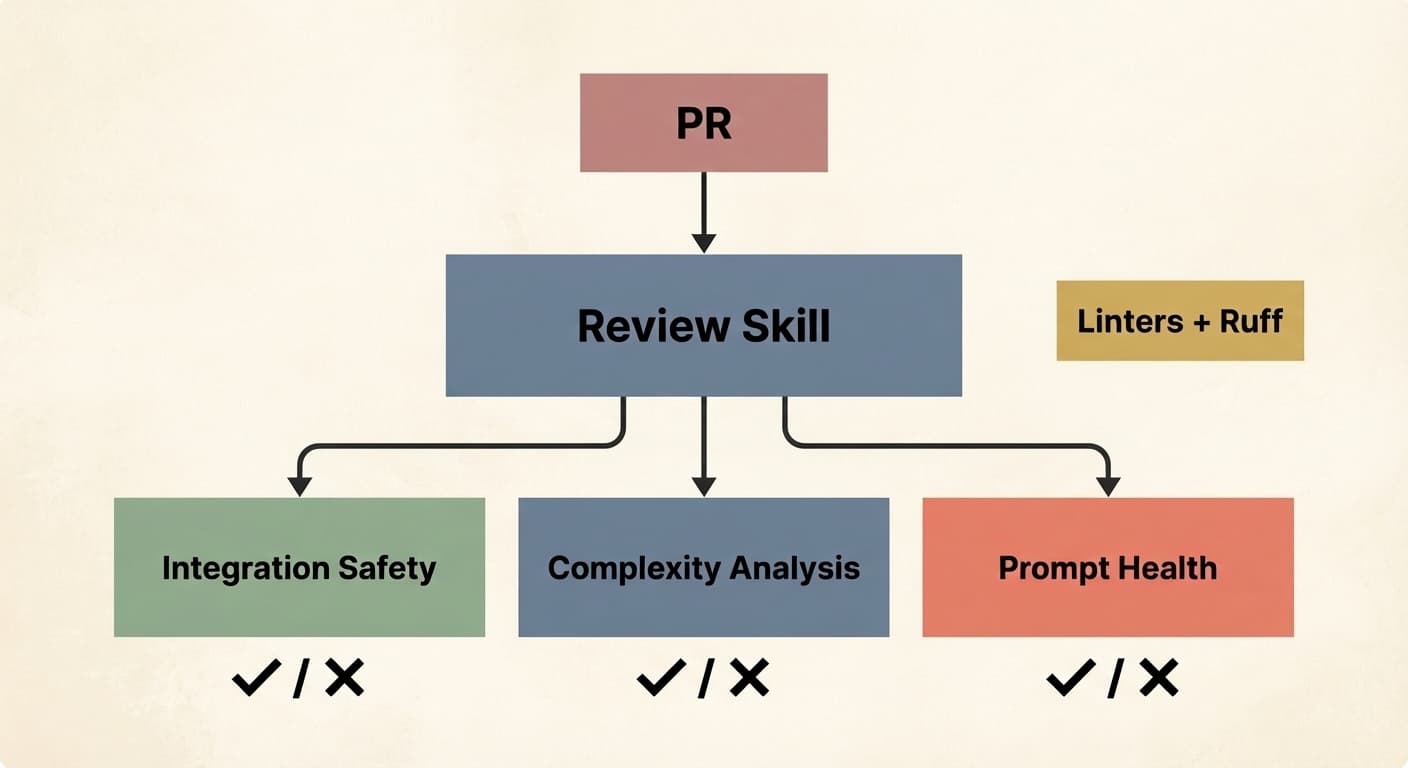
Почему столько вложений в навык ревью? Потому что когда агенты начинают генерировать PR в объёме, человеческое ревью становится узким местом. Автоматическое ревью на основе навыков заменяет ручное.
Ещё один тренд: LLM всё чаще используют CLI-инструменты вместо MCP. Google Workspace CLI, Braintrust CLI, agent-browser. Причина: экономия токенов. MCP-серверы инжектят полные схемы инструментов в контекст на каждом шаге, даже если агент ими не пользуется. CLI работает наоборот: агент запускает конкретную команду, и только релевантный вывод попадает в контекстное окно.
Уровни 3-5 — это фундамент для всего, что дальше. Если контекст шумный, промпты недоспецифицированы, а инструменты описаны плохо, уровни 6-8 только усиливают хаос.
Уровень 6: Harness engineering и петли обратной связи
Вот тут начинается серьёзное ускорение.
Context engineering — это про то, что модель видит. Harness engineering — про всю среду, инструментарий и петли обратной связи, которые позволяют агентам работать надёжно без вмешательства человека. Дай агенту не только редактор, а весь feedback loop.
Команда OpenAI Codex подключила Chrome DevTools, инструменты наблюдаемости и навигацию по браузеру к агентному рантайму. По одному промпту агент может воспроизвести баг, записать видео, реализовать фикс, провалидировать его через UI, открыть PR, ответить на комментарии и замёрджить. Эскалация к человеку только когда нужно суждение, а не механическая работа.
Ключевая концепция здесь: backpressure. Автоматические механизмы обратной связи (тесты, линтеры, pre-commit хуки, система типов), которые позволяют агентам обнаруживать и исправлять ошибки без человека. Хочешь автономности — нужна backpressure. Иначе получишь генератор мусора.
Это касается и безопасности. CTO Vercel аргументирует, что агенты, генерируемый код и секреты должны жить в разных доменах доверия. Prompt injection в лог-файле может заставить агента слить креденшиалы, если всё работает в одном контексте безопасности.
Два практических принципа:
- Пропускная способность важнее перфекции. Когда каждый коммит должен быть идеальным, агенты зацикливаются на одном баге и перезаписывают фиксы друг друга. Лучше допускать мелкие ошибки и делать финальный проход перед релизом.
- Ограничения работают лучше инструкций. Пошаговые промпты («сделай A, потом B, потом C») устаревают. Агенты зацикливаются на списке и игнорируют всё, что не в нём. Лучше: «вот что я хочу, работай, пока не пройдёшь все тесты».
Вторая половина harness engineering: агент должен уметь навигировать по репозиторию без тебя. Подход OpenAI: AGENTS.md на ~100 строк как оглавление со ссылками на структурированную документацию. Свежесть документации — часть CI, а не результат ручных обновлений, которые быстро устаревают.
Уровень 7: Фоновые агенты
Провокационный тезис Bassim: plan mode умирает.
Борис Черный, создатель Claude Code, до сих пор начинает 80% задач в plan mode. Но с каждым новым поколением моделей процент успешного выполнения с первого раза после планирования растёт. Мы приближаемся к точке, когда plan mode как отдельный человеческий шаг становится необязательным. Не потому что планирование не важно, а потому что модели научились планировать сами.
Важная оговорка: это работает только если ты выполнил работу на уровнях 3-6. Чистый контекст, явные ограничения, хорошо описанные инструменты, тугие петли обратной связи. Если этого нет, план придётся проверять вручную.
Когда агент может спланировать и выполнить задачу без твоего одобрения, он может работать асинхронно, пока ты занимаешься чем-то другим. Это критический переход: от «несколько вкладок, между которыми я переключаюсь» к «работа, которая происходит без меня».

Но чем больше агентов запускаешь параллельно, тем больше замечаешь, куда уходит время: координация, последовательность задач, проверка результатов. Ты больше не пишешь код. Ты стал менеджером. Нужен оркестратор, который занимается диспетчеризацией, а ты остаёшься на уровне намерений. Bassim построил для этого Dispatch, навык для Claude Code, который превращает сессию в командный центр.
Мощный паттерн на этом уровне: разные модели для разных задач. Лучшие команды не состоят из одинаковых людей. То же работает с LLM. Opus для реализации, Gemini для исследования, Codex для ревью. Совокупный результат сильнее, чем у любой одной модели. Подробнее об этом я писал в паттернах воркфлоу AI-агентов.
И критически важно: отделяй реализацию от ревью. Если одна и та же модель реализует и оценивает свою работу, она предвзята. Будет замалчивать проблемы и рапортовать, что всё готово. Это не злой умысел, а та же причина, по которой ты не проверяешь свой собственный экзамен. Пусть другая модель (или другой инстанс с промптом для ревью) делает проверку.
Фоновые агенты также открывают путь к связке CI + AI. Бот, который регенерирует документацию при каждом мёрдже и открывает PR на обновление CLAUDE.md. Секьюрити-ревьюер, который сканирует PR и открывает фиксы. Dependency-бот, который реально обновляет пакеты и гоняет тесты, а не просто флагает.
Уровень 8: Автономные команды агентов
Этот уровень пока никто не освоил. Активный фронтир.
На уровне 7 у тебя оркестратор, который раздаёт задачи воркерам (hub-and-spoke). Уровень 8 убирает это узкое место. Агенты координируются напрямую: берут задачи, делятся находками, флагают зависимости, разрешают конфликты без маршрутизации через центральный оркестратор.
Экспериментальная фича Agent Teams в Claude Code — ранняя реализация: несколько инстансов работают параллельно над общей кодовой базой, каждый в своём контекстном окне, общаются напрямую. Anthropic использовали 16 параллельных агентов, чтобы с нуля собрать C-компилятор, способный скомпилировать Linux. Cursor запускал сотни агентов на протяжении недель, чтобы построить браузер с нуля и мигрировать кодовую базу с Solid на React.
Но швы видны. Cursor обнаружил, что без иерархии агенты становятся risk-averse и крутятся без прогресса. Агенты Anthropic ломали существующий функционал, пока не добавили CI-пайплайн для предотвращения регрессий.
Думаю, Bassim прав: для повседневной работы уровень 7 — это текущий потолок практической пользы. Уровень 8 слишком медленный, слишком затратный по токенам и не окупается за пределами лунных проектов вроде компиляторов. Со временем это изменится, но пока энергию стоит вкладывать в седьмой уровень.
А что дальше?
Голосовое взаимодействие с агентом. Не voice-to-text, а полноценный разговор: смотришь на приложение, описываешь изменения вслух, наблюдаешь, как они применяются.
И нет, идеальный one-shot, когда ты говоришь что хочешь и AI выдаёт готовый результат за один проход, пока не реалистичен. Люди никогда точно не знают, чего хотят. Софт всегда был итеративным и останется таким. Просто станет значительно проще и быстрее.
Что ещё почитать
- 10 воркфлоу Claude Code на каждый день — практические примеры работы с AI-агентом в терминале
- 3 паттерна воркфлоу AI-агентов — single agent, pipeline, orchestrator: когда какой выбирать
- Code Review в Claude Code — как работает автоматическое ревью PR
- Топ-6 AI-агентов для кода в 2026 — сравнение Claude Code, Cursor, Codex и других