3 паттерна воркфлоу AI-агентов: когда какой использовать
Anthropic выделяют три паттерна воркфлоу AI-агентов, которые покрывают большинство задач на проде. Разбираемся, когда какой использовать и как их комбинировать.


TL;DR: Anthropic выделяет три паттерна воркфлоу для AI-агентов, которые покрывают большинство продакшн-задач: последовательный, параллельный и evaluator-optimizer. Начинать стоит с самого простого — и усложнять, только когда это реально нужно.
Если ты строишь что-то на AI-агентах, рано или поздно встаёт вопрос: как организовать их работу? Один агент делает всё сам? Несколько работают параллельно? Или один пишет, а другой проверяет?
Anthropic поработали с десятками команд, которые запускают агентов в проде, и свели всё к трём базовым паттернам. Мне нравится такой подход: не 15 вариантов на все случаи жизни, а три рабочих шаблона, которые можно комбинировать.
Как воркфлоу и агенты работают вместе?
Думаю, тут важно разделить два понятия. Полностью автономный агент сам решает, какие инструменты использовать, в каком порядке выполнять задачи и когда остановиться. Воркфлоу добавляет структуру: задаёт общий поток, определяет чекпоинты и границы.
Хорошая аналогия — сборочная линия на заводе. Каждый работник на своей станции принимает решения по своей задаче, но общий порядок операций спроектирован заранее. С AI-воркфлоу то же самое. Агент умный на каждом шаге, а весь процесс идёт по заданному маршруту.
Три паттерна: когда какой выбирать
Anthropic выделяют три паттерна, которые чаще всего встречаются в продакшне. Это не жёсткие шаблоны, а строительные блоки. Их можно комбинировать и вкладывать друг в друга.
| Паттерн | Какую задачу решает | Когда использовать | Минус | Плюс |
|---|---|---|---|---|
| Последовательный | Шаги зависят друг от друга: шаг Б ждёт результат шага А | Пайплайны данных, цепочки черновик-ревью-финал | Добавляет задержку — каждый шаг ждёт предыдущий | Точность выше — каждый агент фокусируется на одном |
| Параллельный | Задачи независимы, но делать по одной — медленно | Оценка по нескольким критериям, код-ревью, анализ документов | Дороже — несколько одновременных API-вызовов | Быстрее и удобнее для разных команд разработки |
| Evaluator-optimizer | Первый черновик недостаточно хорош | Техническая документация, клиентские коммуникации, генерация кода | Расход токенов x2-3, время итераций | Качество выше за счёт структурированной обратной связи |
Последовательный воркфлоу
Самый простой паттерн. Задачи выполняются в заданном порядке, выход одного шага становится входом следующего. Данные текут слева направо, как пайплайн.
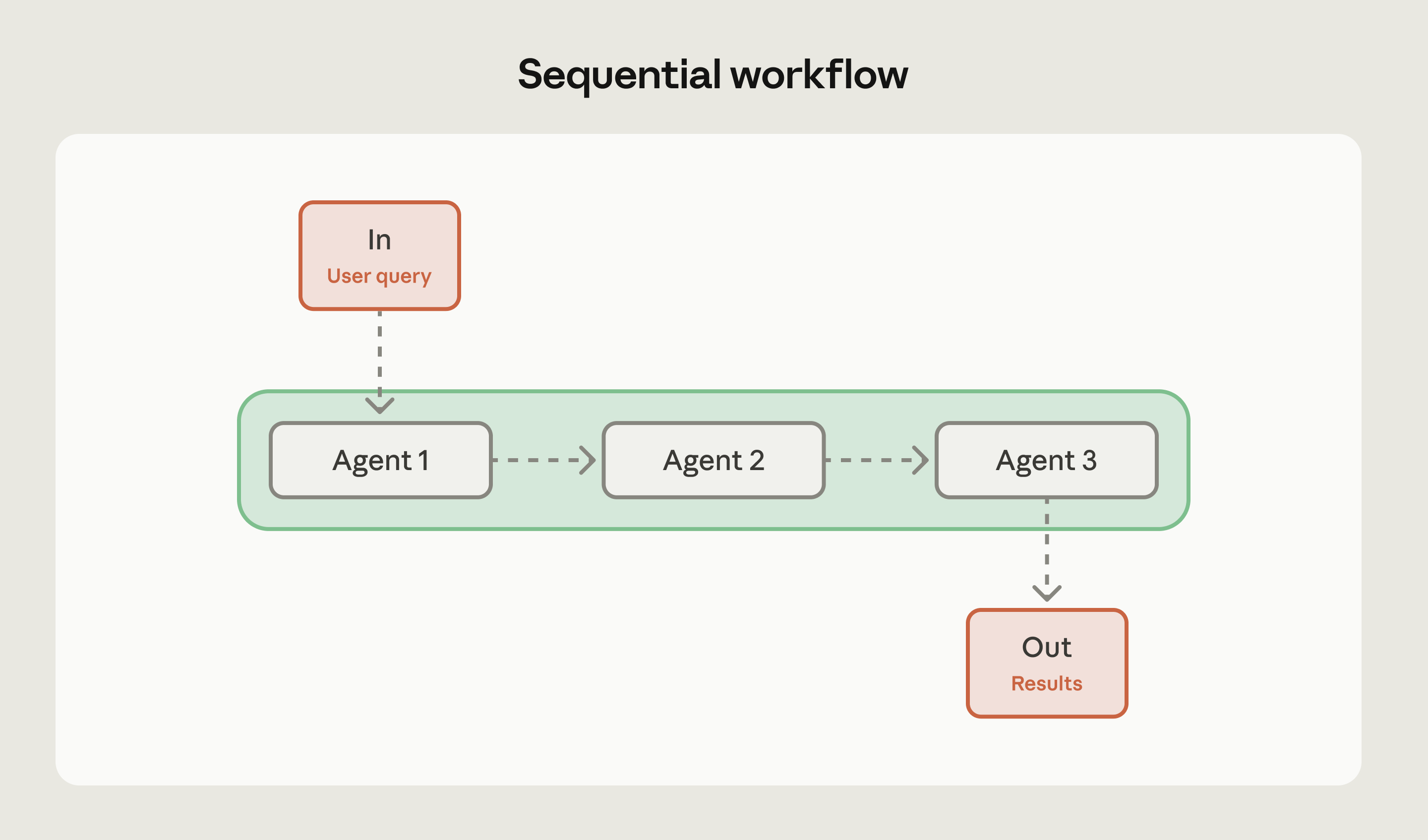
Подходит для многоступенчатых процессов, где каждый шаг зависит от предыдущего: пайплайны данных, цепочки «черновик → ревью → финал».
Пример: генерация маркетингового текста, а потом перевод на несколько языков. Или модерация контента — извлечь, классифицировать, применить правила, маршрутизировать.
Anthropic советуют сначала попробовать всё в одном промпте. Справляется? Задача решена. Разбивать на шаги стоит, только когда один агент не вытягивает.
Я бы добавил, что это вообще самый недооценённый совет во всей теме агентов. Хочется сразу строить сложную архитектуру с пятью шагами, а достаточно было нормально написать промпт.
Параллельный воркфлоу
Тут несколько агентов работают одновременно над независимыми задачами. Не ждут друг друга, каждый делает своё, потом результаты собираются вместе.
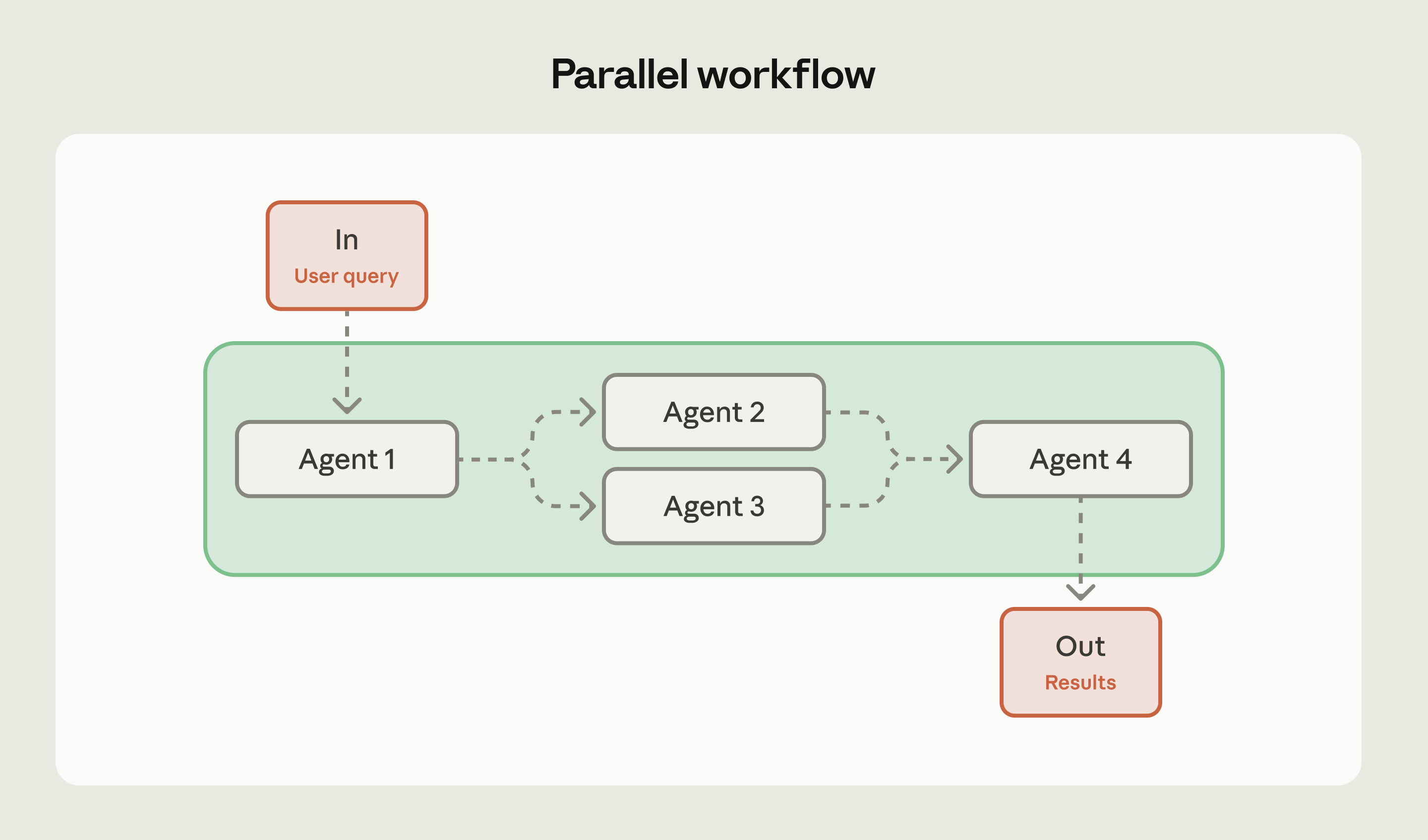
По сути это fan-out/fan-in из распределённых систем. Раздаёшь работу нескольким агентам, собираешь результаты, агрегируешь.
Хорошо ложится на задачи, где нужно оценить что-то по нескольким измерениям сразу. Код-ревью, где один агент ищет уязвимости, другой проверяет стиль, третий — перформанс. Или анализ документа, где параллельно извлекаются темы, тональность и факты.
Но тут есть подвох. Прежде чем запускать параллельных агентов, нужно решить, как собирать результаты. Берём мнение большинства? Средний скор уверенности? Доверяем самому специализированному? Без этого плана получишь кучу противоречивых ответов и непонятно, что с ними делать.
Evaluator-optimizer
Мой любимый паттерн, если честно. Два агента работают в цикле: один генерирует, другой оценивает по заданным критериям. Генератор дорабатывает по фидбеку, и так до достижения порога качества или лимита итераций.
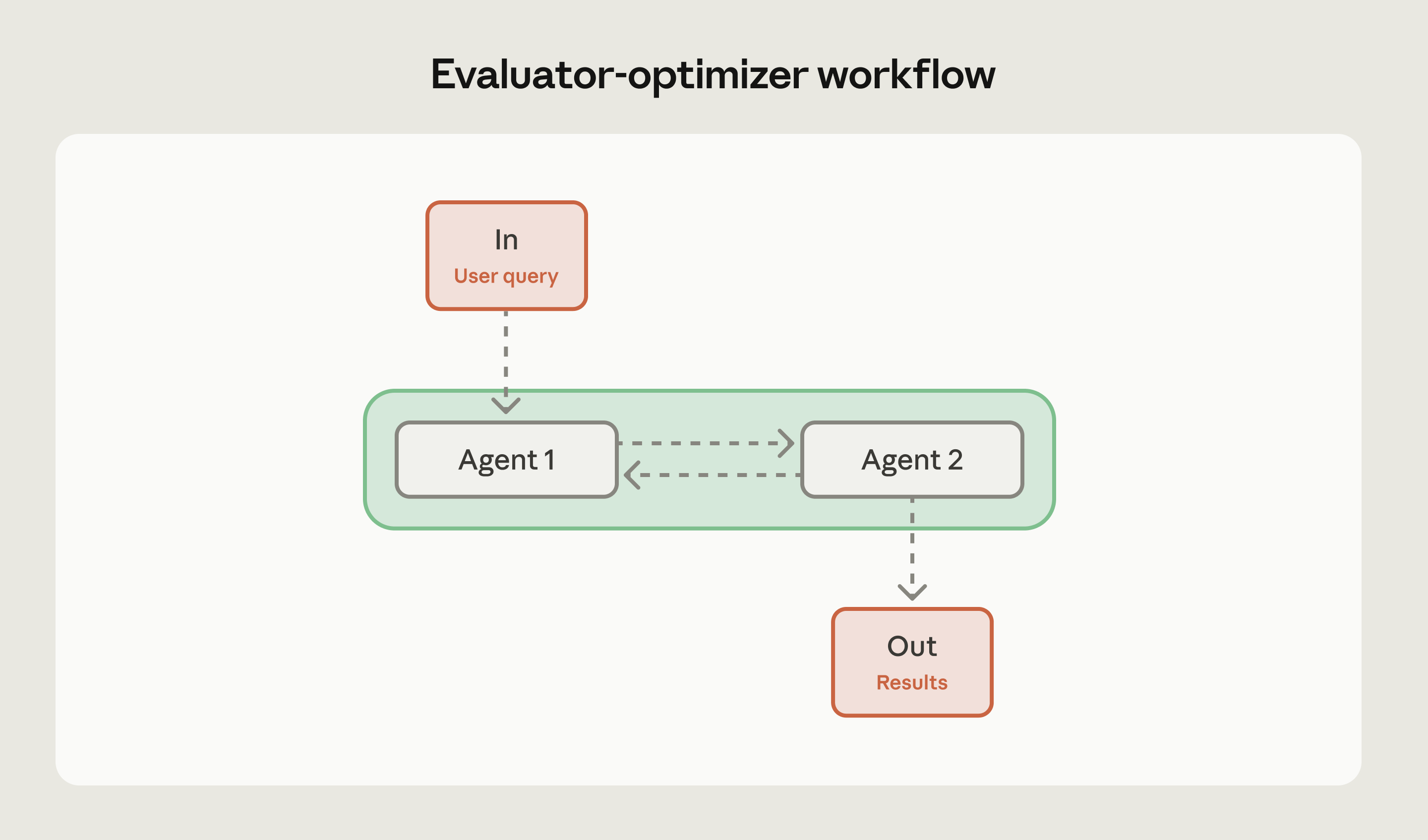
Генерация и оценка — разные когнитивные задачи. Разделяешь их, и каждый агент делает одно, но хорошо.
Работает для генерации кода с жёсткими требованиями, клиентских коммуникаций, где важен тон, и вообще любых задач, где первый черновик стабильно не дотягивает.
Конкретный пример: агент пишет API-документацию, оценщик сверяет с кодовой базой на полноту и точность. Или агент генерирует SQL-запрос, а оценщик проверяет на инъекции и эффективность.
Как выбрать паттерн?
Anthropic предлагают простой алгоритм:
- Попробуй решить задачу одним вызовом агента. Если получилось — не нужен воркфлоу вообще
- Есть чёткие последовательные зависимости? Бери sequential
- Подзадачи независимы и нужна скорость? Бери parallel
- Качество заметно растёт от итераций? Бери evaluator-optimizer
Паттерны можно комбинировать. Evaluator-optimizer с параллельной оценкой, когда несколько оценщиков одновременно проверяют разные аспекты. Или последовательный воркфлоу с параллельным шагом на одном из этапов.
Не усложняй ради усложнения. Параллелизация не даёт ощутимого прироста? Не добавляй. Первый черновик и так нормальный? Не строй цикл оценки.
Вывод
По моему опыту, 80% задач с агентами решаются последовательным воркфлоу или вообще одним вызовом. Параллельный нужен, когда упираешься в скорость. А evaluator-optimizer — когда реально нужно качество выше, чем даёт один проход.
Главное из статьи Anthropic: начни с простого. Один агент, один промпт. Не вытягивает — добавь структуру. Три паттерна дают понятные пути масштабирования, и не нужно переписывать всё с нуля.
Что ещё почитать
- Память AI-агентов: контекст, RAG, графы и mem0 — как агенты запоминают информацию между сессиями
- Топ-6 AI-агентов для кода в 2026 — сравнение инструментов, которые используют эти паттерны
- Code Review в Claude Code — пример sequential-воркфлоу на практике