GPT-5.5 и GPT-5.5 Pro: обзор новых моделей OpenAI
OpenAI выпустила GPT-5.5 и GPT-5.5 Pro. Обгоняет Claude Opus 4.7 на Terminal-Bench (82,7% vs 69,4%), 400K контекст в Codex. Что реально изменилось.


TL;DR: OpenAI выпустила GPT-5.5 и GPT-5.5 Pro. Новая модель берёт 82,7% на Terminal-Bench 2.0 против 69,4% у Claude Opus 4.7, 73,1% на Expert-SWE и 84,9% на GDPval. В Codex появился контекст 400K, в API будет 1M. Цены в API — $5 за 1M input и $30 за output (обычная версия), $30/$180 за Pro. В ChatGPT раскатывают Plus, Pro, Business и Enterprise.
23 апреля 2026 OpenAI показала GPT-5.5. Релиз совпал с той же неделей, на которой они выкатили ChatGPT Images 2.0 и ужесточили safety в Codex. По бенчмаркам GPT-5.5 обходит Claude Opus 4.7 и Gemini 3.1 Pro на большинстве тестов, связанных с кодингом и агентными задачами. Но интересно не это. Главный сдвиг в том, что модель стала лучше держать длинный контекст работы, меньше тратит токенов и увереннее проходит многошаговые сценарии без «отвалиться на середине».
Разберём, что там по цифрам, где реально прирост, и стоит ли переходить.
Что изменилось по сравнению с GPT-5.4
Главный тезис OpenAI: GPT-5.5 «понимает намерение» лучше, берёт на себя больше работы, меньше нуждается в ручном управлении каждым шагом. По цифрам это превращается в такие улучшения против GPT-5.4:
| Метрика | GPT-5.5 | GPT-5.4 | Прирост |
|---|---|---|---|
| Terminal-Bench 2.0 | 82,7% | 75,1% | +7,6 п.п. |
| Expert-SWE (internal) | 73,1% | 68,5% | +4,6 п.п. |
| OSWorld-Verified (computer use) | 78,7% | 75,0% | +3,7 п.п. |
| ARC-AGI-2 | 85,0% | 73,3% | +11,7 п.п. |
| MRCR v2, 512K-1M | 74,0% | 36,6% | +37,4 п.п. |
| CTF Internal (кибер) | 88,1% | 83,7% | +4,4 п.п. |
Цифры OpenAI, опубликованы в анонсе. Самый яркий прирост — на длинном контексте ближе к миллиону токенов. Там GPT-5.4 откровенно сыпался, а GPT-5.5 держит 74% точности. Думаю, именно это сильнее всего почувствуют те, кто работает с большими кодовыми базами и длинными документами.
Ещё один важный нюанс, который OpenAI подчёркивает отдельно. GPT-5.5 по скорости на токен сопоставим с GPT-5.4, хотя модель умнее и больше. Обычно более мощная модель проседает по латентности. Здесь нет. Плюс она тратит меньше токенов на те же задачи в Codex, что частично компенсирует рост цены.
Бенчмарки против Claude Opus 4.7 и Gemini 3.1 Pro
Здесь два сюжета одновременно. Где OpenAI вырвалась вперёд, а где Anthropic или Google всё ещё держат корону.
GPT-5.5 ведёт:
- Terminal-Bench 2.0 — 82,7% против 69,4% у Claude Opus 4.7 и 68,5% у Gemini 3.1 Pro
- GDPval (профессиональная работа) — 84,9% против 80,3% и 67,3%
- CyberGym — 81,8% против 73,1% у Claude
- FrontierMath Tier 4 — 35,4% против 22,9% у Claude и 16,7% у Gemini
- OfficeQA Pro — 54,1% против 43,6% у Claude, 18,1% у Gemini
- Toolathlon — 55,6% против 48,8% у Gemini
Claude Opus 4.7 или Gemini 3.1 Pro ведут:
- SWE-Bench Pro (Public) — 64,3% у Opus 4.7 против 58,6% у GPT-5.5
- Humanity's Last Exam (без tools) — 46,9% у Opus 4.7 против 41,4% у GPT-5.5
- BrowseComp — 90,1% у GPT-5.5 Pro, но в обычной версии Claude 79,3% против 84,4% у GPT-5.5
- ARC-AGI-1 — 98,0% у Gemini 3.1 Pro против 95,0% у GPT-5.5
- MCP Atlas — 79,1% у Claude и 78,2% у Gemini против 75,3% у GPT-5.5
Картина неоднородная. По публичному SWE-Bench Pro Claude Opus 4.7 всё ещё чемпион, и это важный тест реальных багфиксов на GitHub. По общим рассуждениям в Humanity's Last Exam Anthropic тоже впереди. Но везде, где задача подразумевает длинный цикл с инструментами, компьютером, терминалом — GPT-5.5 идёт вперёд.
По-моему, это не «одна модель всех побила», а «OpenAI отвоевала позиции в агентном кодинге и офисных задачах». SWE-Bench Pro и академические эссе всё ещё за Anthropic. Подробнее про конкурента — в обзоре Claude Opus 4.7.
Codex и агентный кодинг
Самое громкое место в анонсе. OpenAI настаивает, что GPT-5.5 — их «самая сильная агентная кодинг-модель на сегодня». Звучит как маркетинг, но тестеры подтверждают.
Дэн Шиппер, CEO Every, говорит, что GPT-5.5 — «первая кодинг-модель с серьёзной концептуальной ясностью». Он запустил приложение, несколько дней дебажил проблему, потом позвал сильного инженера на переписывание. Чтобы проверить GPT-5.5, Шиппер отмотал всё назад и дал модели сломанный проект. GPT-5.4 не справился. GPT-5.5 выдал такое же решение, как инженер.
Пьетро Скирано, CEO MagicPath, смержил ветку с сотнями изменений во фронтенде и рефакторингом в основную ветку, которая тоже далеко ушла. За двадцать минут, с одного раза.
Один инженер из NVIDIA в отзыве OpenAI сказал, что «потеря доступа к GPT-5.5 ощущается как потеря конечности». Слегка драматично, но штука в том, что это говорят не случайные блогеры, а люди, которые до этого год работали с GPT-5.4.
Майкл Труэлл, CEO Cursor:
GPT-5.5 заметно умнее и настойчивее GPT-5.4, с более сильным кодингом и надёжным использованием инструментов. Она дольше держится за задачу, не останавливаясь на середине, что особенно важно для сложной длительной работы, которую наши пользователи делегируют в Cursor.
Плюс OpenAI раскатывает в Codex контекст на 400K токенов и Fast mode, который в 1,5 раза быстрее генерирует токены за 2,5-кратную цену. Кому нужно быстрее — пожалуйста, дорого.
Работа с компьютером, офисом и documents
Здесь логика такая же, как в кодинге, только вместо IDE — экран ноутбука. GPT-5.5 лучше понимает, что на экране, куда кликать, как двигаться между приложениями. На OSWorld-Verified набрала 78,7% — тот же уровень, что Claude Opus 4.7 (78,0%), но с существенно меньшими токеновыми затратами, если верить OpenAI.
Внутри самой OpenAI больше 85% сотрудников еженедельно пользуются Codex. Не только инженеры — финансисты, маркетинг, data science, PR. Пара показательных примеров из анонса:
- Команда Comms проанализировала шесть месяцев запросов на выступления, построила скоринг и риск-фреймворк, подключила Slack-агента. Низкорисковые запросы он обрабатывает сам, сложные маршрутизирует людям
- Финансисты прогнали 24 771 налоговую форму K-1 на 71 637 страниц за сроки на две недели короче прошлого года
- Сотрудник Go-to-Market автоматизировал еженедельные бизнес-отчёты и экономит 5–10 часов в неделю
Я про подобное писал в обзоре Claude Managed Agents — там тоже про автоматизацию рутинных бизнес-задач, только через API Anthropic. Тренд очевидный: LLM перестают быть «чат-ботом для ответов» и становятся исполнителями, которые реально делают работу.
Наука: биология, математика, биоинформатика
GPT-5.5 Pro — это пятая передача для задач, где GPT-5.5 уже тормозит. Особенно на научных задачах.
На GeneBench (многошаговый анализ генетических данных) GPT-5.5 Pro показала 33,2% против 25,6% у GPT-5.4 Pro. На BixBench (биоинформатика) обычная GPT-5.5 взяла 80,5% против 74,0%. На FrontierMath Tier 4 — 39,6% у Pro-версии.
Деря Унутмаз, иммунолог из Jackson Laboratory, прогнал через GPT-5.5 Pro датасет экспрессии генов на 62 образца и 28 000 генов. Модель собрала детальный отчёт, который, по его словам, команда делала бы месяцами.
Бартош Наскрецки, математик из Польши, за 11 минут сгенерил через Codex приложение для алгебраической геометрии — визуализация пересечения квадратичных поверхностей с конверсией в уравнение Вейерштрасса. Один промпт.
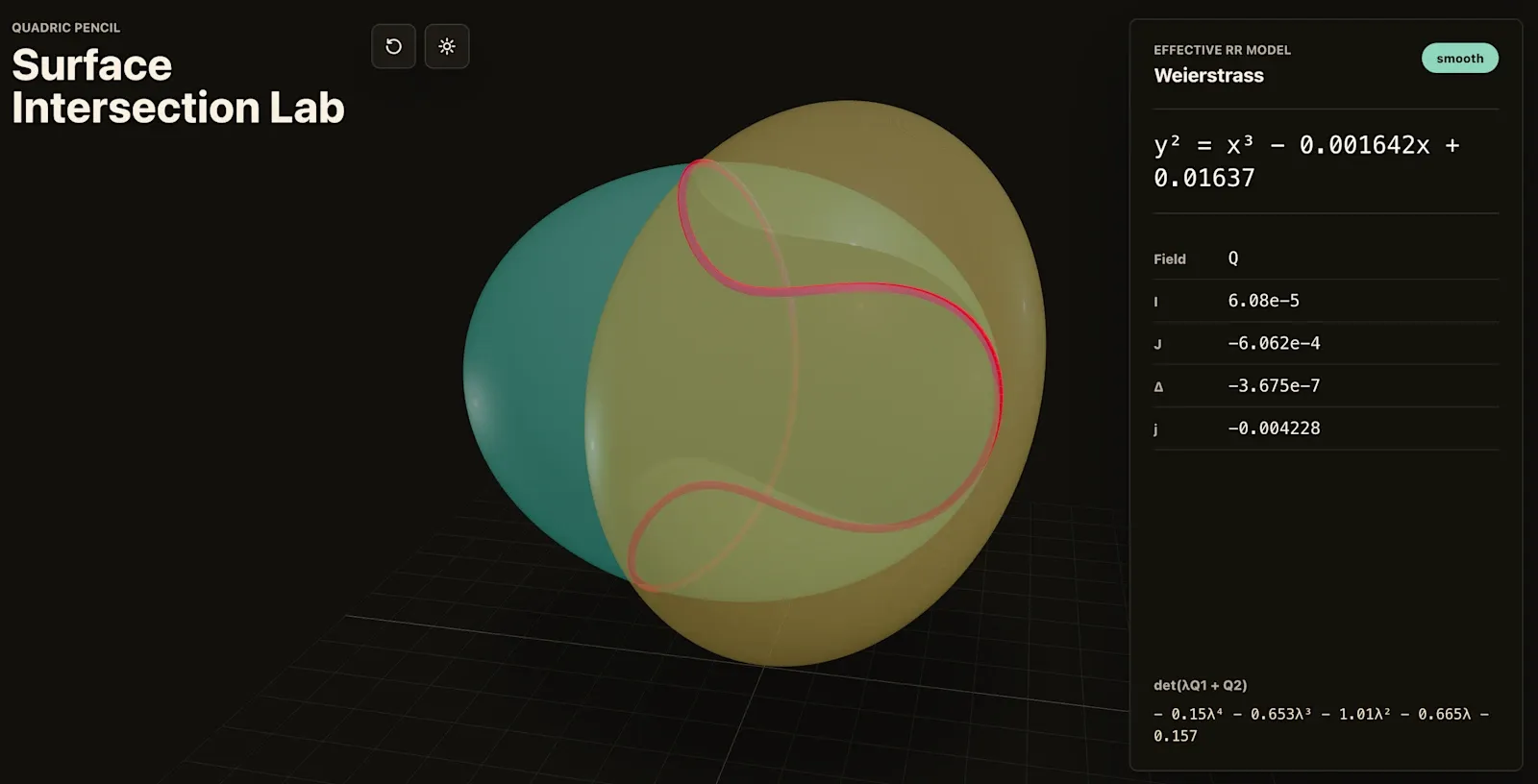
Отдельный интересный кейс от OpenAI: внутренняя версия GPT-5.5 с кастомной обёрткой нашла новое доказательство асимптотического факта про внедиагональные числа Рамсея. Результат проверен в Lean. То есть модель выдала не код и не пересказ, а реальный математический аргумент в центральной области комбинаторики — для топовой модели такое впервые.
Думаю, для исследователей с конкретными узкими задачами Pro-версия станет рабочим инструментом, а не демо. Вопрос только в цене.
Кибербезопасность: High в Preparedness
OpenAI честно говорит, что кибер-способности GPT-5.5 они считают High по их Preparedness Framework. Не Critical, но step up по сравнению с GPT-5.4.
Что это означает на практике:
- Жёстче фильтры на рискованные кибер-запросы, на подозрительные паттерны и на повторное злоупотребление
- Для верифицированных защитников запущен Trusted Access — можно подать заявку на
chatgpt.com/cyberи получить меньше отказов для легитимной защитной работы - OpenAI работает с правительствами по защите критической инфраструктуры
На CyberGym GPT-5.5 взяла 81,8% против 73,1% у Claude Opus 4.7. На внутреннем CTF — 88,1%. Это уровень, когда модель реально полезна для red team и blue team, и именно поэтому OpenAI отдельно затянула safety.
Тема сложная: чем мощнее модель в кибере, тем больше шансов, что ей воспользуются злоумышленники, и тем важнее давать её защитникам. OpenAI выбирает путь «trusted access с верификацией». Anthropic в Claude Opus 4.7 пошла чуть другим путём (больше авто-модерации без выдачи cyber-permissive вариантов). Какой подход окажется жизнеспособным — покажет ближайший год.
Цены и где доступ
В ChatGPT GPT-5.5 Thinking раскатывают прямо сейчас на Plus, Pro, Business и Enterprise. GPT-5.5 Pro — только Pro, Business, Enterprise.
В Codex доступ шире: Plus, Pro, Business, Enterprise, Edu, Go. Контекст 400K, есть Fast mode — 1,5× скорость за 2,5× цены.
В API GPT-5.5 ещё не появилась, «скоро будет». По ценам OpenAI ориентирует так: обычная GPT-5.5 пойдёт по $5 за 1M input-токенов и $30 за output, контекст 1M. Pro-версия — $30 за input и $180 за output. Batch и Flex идут за половину обычной цены, Priority — в 2,5× дороже, если нужна приоритетная обработка.
Для сравнения, Claude Opus 4.7 в API стоит дороже на input ($15 против $5), но output сопоставимый. GLM-5.1, про которую я писал раньше, идёт в разы дешевле при 94,6% перформанса Opus 4.7 в кодинге. Так что для тех, кто чувствителен к цене, картина неоднозначная. Но если нужна максимальная точность на агентных задачах, GPT-5.5 сейчас выглядит как самый сильный выбор.
Вывод
GPT-5.5 — это ещё плюс один шаг в сторону агентов, которые реально доводят работу до конца. По бенчмаркам OpenAI обогнала Claude Opus 4.7 и Gemini 3.1 Pro в агентном кодинге, офисных задачах и кибер-тестах. В публичном SWE-Bench Pro Claude ещё держит первое место, так что никакого «всё, Anthropic в нокауте» не случилось. Просто в очередной раз поменялись позициями.
Что реально круто: модель меньше «сдаётся на середине», лучше держит длинный контекст, эффективнее по токенам. Для тех, кто пишет код в Cursor, Codex или собирает агентов, это самое заметное улучшение. Для исследователей Pro-версия открывает задачи, которые раньше не вытягивали вообще.
По цене GPT-5.5 стала дороже GPT-5.4, но OpenAI настаивает, что за счёт лучшей токен-эффективности в итоге выходит дешевле. Поверим и посмотрим. На полноценные выводы нужно несколько недель реальной работы.
Если хочется конкретики: я бы сейчас пробовал GPT-5.5 в Codex на одной рабочей задаче и сравнил с Claude Opus 4.7 и тем, чем вы пользуетесь сейчас. Бенчмарки бенчмарками, но только на своих сценариях видно, где модель реально тянет.
Что ещё почитать
- Claude Opus 4.7: обзор новой модели Anthropic — главный конкурент, чемпион SWE-Bench Pro
- GLM-5.1: китайская модель на 94,6% от Claude Opus в кодинге — дешёвая альтернатива для тех, кто считает токены
- Qwen 3.6-Plus: Alibaba бросает вызов Claude в агентном кодинге — ещё одна агентная модель из Китая
- ChatGPT Images 2.0: новый генератор OpenAI — что ещё OpenAI выкатила в эту же неделю