Qwen3-Coder-Next — маленькая модель, которая кодит как большая
Alibaba выпустила Qwen3-Coder-Next — MoE-модель с 3B активных параметров, которая на coding-бенчмарках конкурирует с моделями в 10-20 раз крупнее.

TL;DR: Alibaba выпустила Qwen3-Coder-Next — open-weight модель для кодинга с архитектурой MoE (80B параметров, но активны только 3B). Она набирает 70%+ на SWE-Bench Verified и конкурирует с моделями в 10-20 раз крупнее. Доступна бесплатно на Hugging Face.
Когда все гонятся за триллионами параметров, Alibaba пошла в другую сторону. Qwen3-Coder-Next — это попытка доказать, что для хорошего кодинг-агента не обязательно держать в памяти модель размером с небольшой дата-центр. И, судя по бенчмаркам, у них получилось.
Что такое Qwen3-Coder-Next
Qwen3-Coder-Next построена на базе Qwen3-Next-80B-A3B-Base. Если расшифровать название: 80B — это общее количество параметров, A3B — количество активных при инференсе. Модель использует архитектуру Mixture of Experts (MoE) с гибридным вниманием, поэтому при генерации работает только малая часть весов.
На практике это означает одно — модель можно запускать на обычном железе. Ну, относительно обычном. Не нужен кластер GPU за сотни тысяч долларов, как для полноразмерных моделей уровня GPT-5 или Claude Opus.
Веса открыты — можно скачать с Hugging Face или ModelScope. Техрепорт тоже на GitHub.
Как тренировали — ставка на агентный подход
Самое интересное в Qwen3-Coder-Next — не архитектура, а метод обучения. Команда Qwen решила масштабировать не параметры, а агентные сигналы. Вместо того чтобы просто делать модель больше, они собрали огромную коллекцию исполняемых задач с реальными средами.
Обучение шло в несколько этапов:
- Дообучение на code- и agent-ориентированных данных
- Файн-тюнинг на качественных агентных траекториях — записях того, как модель взаимодействует со средой
- Специализация по доменам: софтверная инженерия, QA, веб-разработка
- Дистилляция экспертов в единую модель
Главное тут — модель учили не просто генерировать код, а работать с инструментами, рассуждать на длинной дистанции и выкручиваться, когда что-то пошло не так.
Бенчмарки — где 3B активных бьют 60B
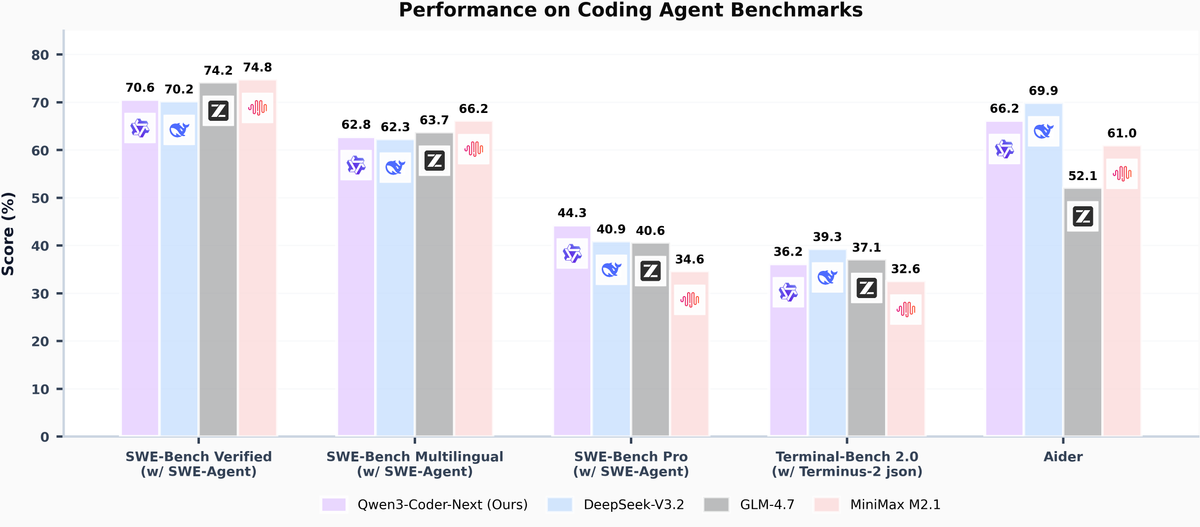
Цифры, честно говоря, впечатляют. Qwen3-Coder-Next набирает больше 70% на SWE-Bench Verified через scaffold SWE-Agent. Для модели с 3B активных параметров это очень достойный результат.
Модель тестировали на нескольких бенчмарках: SWE-Bench (Verified, Multilingual и Pro), TerminalBench 2.0 и Aider. Результаты стабильные — и на мультиязычных задачах, и на более сложном SWE-Bench Pro.
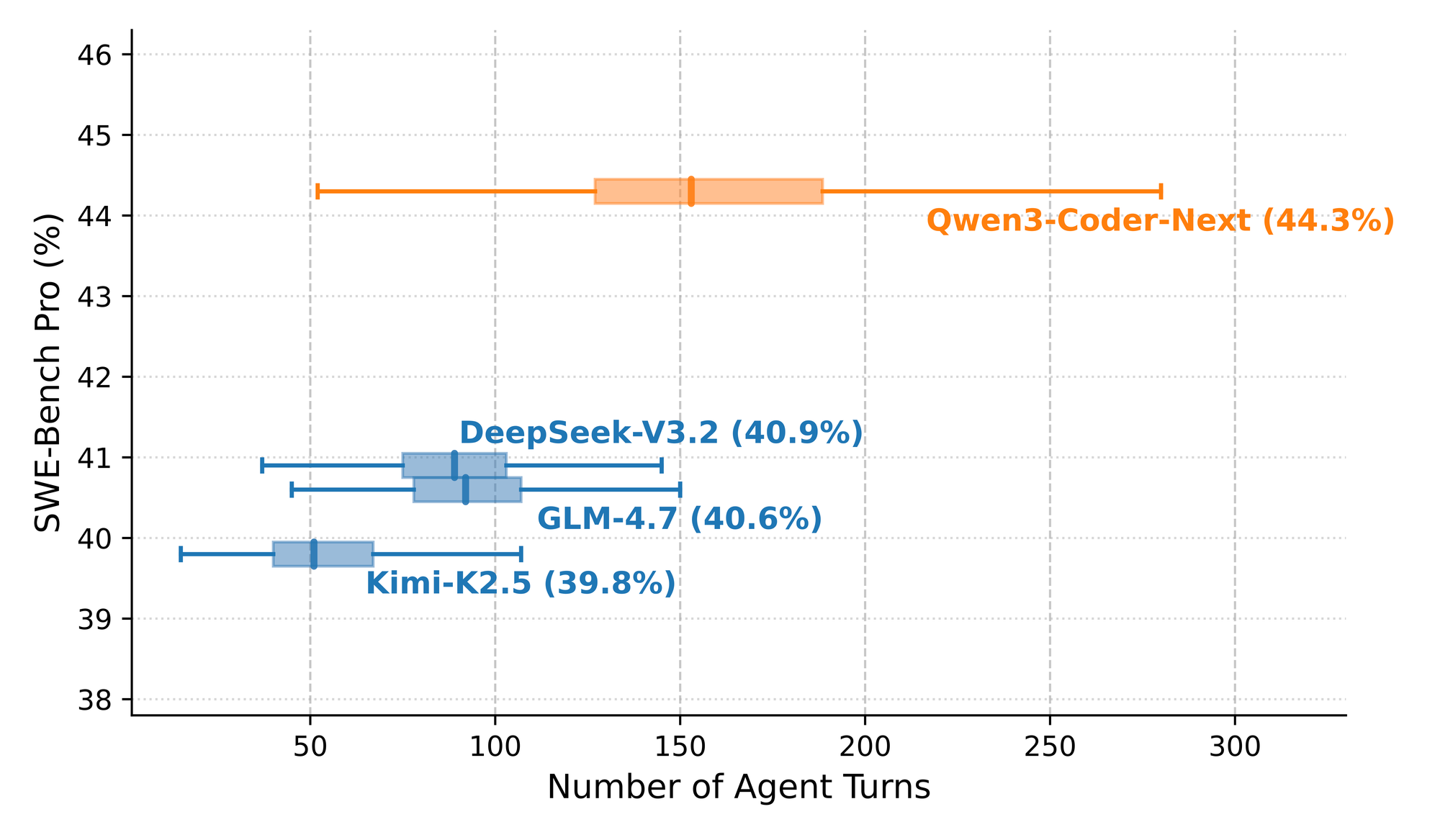
Отдельно интересен график зависимости качества от количества агентных ходов. Чем больше итераций даёшь модели, тем лучше результат на SWE-Bench Pro. Это подтверждает, что модель действительно умеет рассуждать на длинной дистанции, а не просто угадывать с первой попытки.
Эффективность — Парето-фронт для кодинг-агентов
Тут лучше посмотреть на график. Qwen3-Coder-Next с 3B активных параметров выдаёт результаты на уровне моделей, у которых активных параметров в 10-20 раз больше.
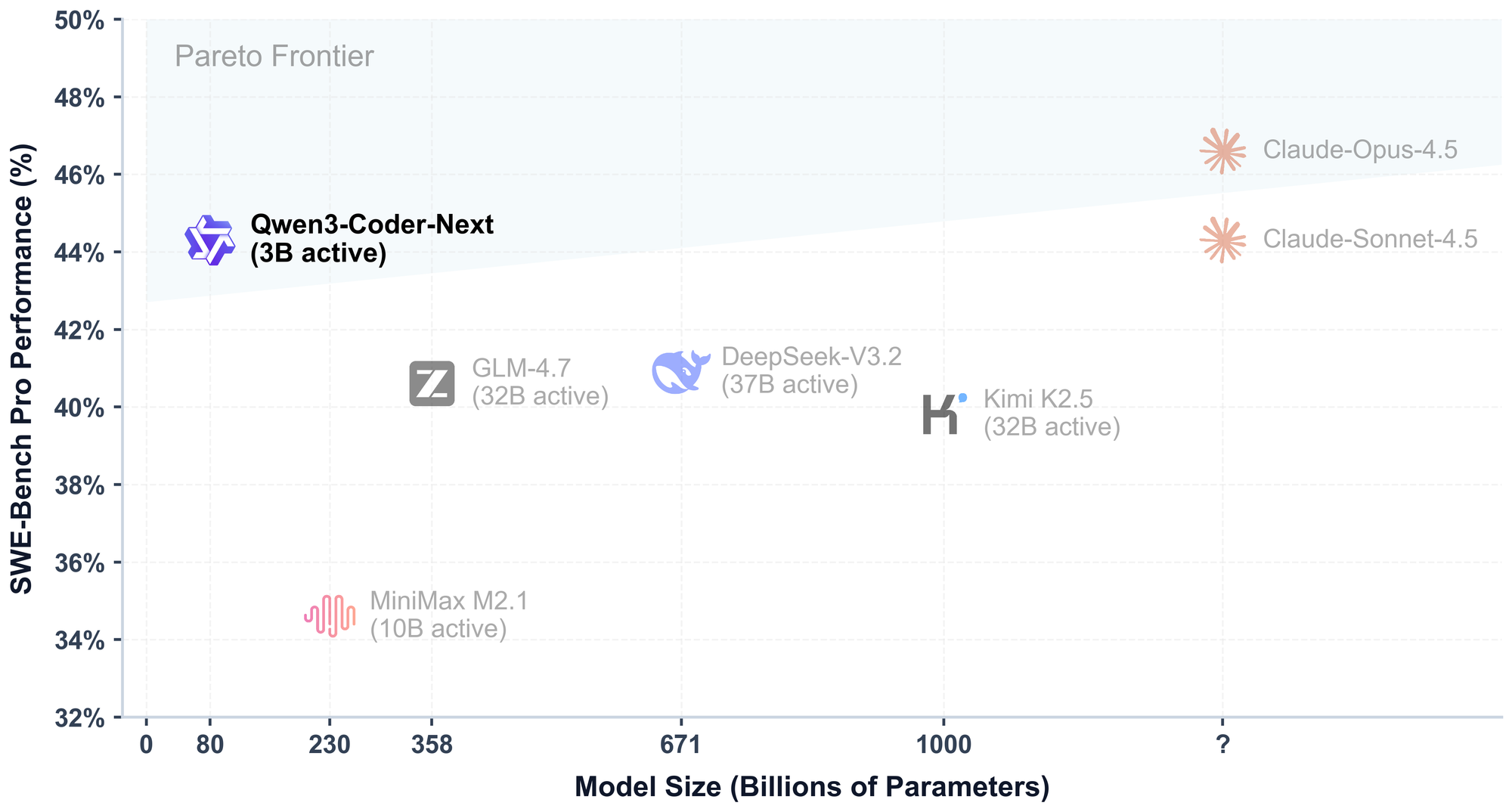
Если хочешь запускать кодинг-агента локально или на VPS, это интересный вариант. Не нужно платить за API крупных провайдеров — разворачиваешь свою модель и работаешь. Правда, насколько бенчмарки переносятся на реальные задачи — вопрос отдельный.
Где пригодится
Команда Qwen показала демо интеграций с несколькими инструментами:
- OpenClaw — open-source фреймворк для AI-агентов
- Cline — расширение для VS Code
- Claude Code — CLI-агент от Anthropic (да, можно подключить стороннюю модель)
- Генерация фронтенда
- Browser Use Agent для автоматизации браузера
Qwen3-Coder-Next заточена именно под агентные сценарии — многоходовые задачи, работа с файловой системой, отладка. Автодополнение тут не главное.
Что не рассказали
Пара моментов, которые стоит иметь в виду. Техрепорт не раскрывает детали обучающих данных — сколько именно задач использовали и из каких репозиториев. Также нет прямого сравнения с GPT-5.3 Codex на одинаковых условиях — бенчмарки запускали через разные scaffolds, что делает честное сравнение сложнее.
Модель пока не тестировали на реальных production-задачах в масштабе. SWE-Bench — это хороший индикатор, но реальная разработка сложнее и разнообразнее.
И ещё — 80B параметров, даже с 3B активными, всё равно требуют заметного объёма RAM для загрузки весов. Это не модель для ноутбука, хотя и не монстр уровня 400B.
Мне нравится направление, в которое двигается Alibaba. Вместо гонки за размером — ставка на умное обучение. 70%+ на SWE-Bench Verified при 3B активных параметрах говорят сами за себя, хотя я бы подождал независимых тестов на реальных проектах.
Если строишь своего кодинг-агента или ищешь альтернативу проприетарным API — стоит попробовать. Веса открыты, скачиваешь и экспериментируешь.
Что ещё почитать
- GPT-5.3 Codex vs Claude Opus 4.6 — сравнение двух главных проприетарных кодинг-моделей
- GLM-5 от Zhipu — лучшая open-source модель 2026 — ещё одна сильная open-source модель из Китая
- Claude Opus 4.6 — самая умная модель Anthropic — обзор проприетарного конкурента
- Kimi K2.5 — китайский open-source с роем из 100 агентов — другой подход к агентным задачам